GAN – AI generująca rzeczywistość


Ostatnio coraz bardziej popularne stają się mechanizmy tworzące różnego rodzaju obrazy ludzi, przedmiotów, czy scen, które naprawdę nigdy nie istniały, lub modyfikujące obrazy istniejących obiektów poprzez dodanie im cech, których wcześniej nie miały.
Idealnym i bardzo popularnym przykładem takiego mechanizmu jest aplikacja FaceApp. Potrafi ona z naszego zdjęcia stworzyć obrazy reprezentujące nas z różnymi cechami. Możemy w niej na przykład dokleić sobie brodę, postarzeć się, odmłodzić, czy dodać inne specjalne cechy, których normalnie nie posiadamy.
Wszystko to jest możliwe dzięki technologii o nazwie GAN (Generative Adversarial Network – generatywne sieci współzawodniczące). W tym artykule chciałbym przybliży�ć Ci, mój drogi czytelniku, tę technologię oraz jej odmiany i pokazać, jak działają.
GAN – Generative Adversarial Network
Na początku przybliżmy sobie mechanizm stojący za generatywnymi sieciami współzawodniczącymi. Wyobraźmy sobie, że posiadamy dwie niezależne sieci neuronowe, pierwszą zwaną dyskryminatorem, którą uczymy rozpoznawać obrazy, i drugą, która uczy się generować obrazy (generatora).
Obydwa modele grają w pewną grę zgodną z teorią gier, gdzie generator próbuje przechytrzyć dyskryminatora, a dyskryminator, posiadając próbki prawdziwych i nieprawdziwych (generowanych) zdjęć, próbuje do tego nie dopuścić.
W trakcie procesu uczenia obydwa modele podnoszą swoje umiejętności. Generator generuje coraz lepsze zdjęcia, a dyskryminator umie coraz lepiej rozpoznawać zdjęcia nieprawdziwe i prawdziwe. W momencie gdy generator zacznie tworzyć tak realistyczne zdjęcia, że dyskryminator nie będzie w stanie odróżnić ich od prawdziwych, model generatywny zostanie w pełni wytrenowany. Dzięki temu będzie on w stanie generować na żądanie zdjęcia, które będą bardzo realistyczne.
Technologia ta została wymyślona w 2014 r. przez Iana Goodfellowa i jego współpracowników. Opublikowali oni całkiem ciekawą pracę naukową opisującą ten koncept.

Lepsza stabilność, szybkość i rozdzielczość – czyli dalszy rozwój technologii
Technologia GAN, pomimo swojego rewolucyjnego podejścia, miała jednak kilka ograniczeń. Wytwarzała ona ostre obrazy, jednak w małych rozdzielczościach i przy niskiej różnorodności. Sam proces uczenia był też niestabilny, pomimo ciągłego rozwoju technologii.
Trzy lata po odkryciu GAN, w 2017 r., Tero Karras wraz z swoim zespołem opisał nową metodę trenowania sieci w pracy „Progressive Growing of GANs for Improved Quality, Stability, and Variation”. Polegać ona miała na ciągłym doskonaleniu generatora i dyskryminatora w trakcie trenowania.
Badacze rozpoczęli trenowanie sieci na zdjęciach niskiej rozdzielczości i stopniowo ją zwiększali poprzez dodawanie kolejnych warstw. Ta przyrostowa metoda pozwoliła procesowi uczenia się najpierw na odkrycie wielkoskalowej struktury rozkładu obrazu, a następnie na zwrócenie uwagi na coraz dokładniejsze szczegóły na obrazie, zamiast uczenia się wszystkiego na raz. To pozwoliło uzyskać niesamowite wyniki i wygenerować bardzo realistyczne obrazy przedstawiające ludzkie twarze.

Dodatkowo mechanizm ten znacząca skrócił czas trenowania. W zależności od rozdzielczości końcowej uległ on skróceniu od 2 do 6 razy. Odkrycie to pozwoliło również na bardzo dynamiczny rozwój technologii i różnego rodzaju zastosowania, dzięki wysokiemu fotorealizmowi generowanych zdjęć. Bardzo dobrze ilustruje to poniższa grafika z opracowania przedstawiającego rozwój AI i ML na przestrzeni ostatnich lat:

Postarzanie twarzy
Przejdźmy teraz do tematu, który ostatnio jest bardzo modny – postarzania twarzy. W 2017 roku poświęcono mu kilka prac badawczych. W jednej z nich zespół z Uniwersytetu z Tennessee poruszył temat z wykorzystaniem tzw. Conditional Adversarial Autoencoder (CAAE).
Mechanizm ten w przeciwieństwie do dotychczasowych modeli nie potrzebował dużej liczby zdjęć twarzy jednej osoby w różnym wieku. Założył on bowiem, że każdą twarz można przedstawić w wielowymiarowej rozmaitości, gdzie przesuwając się w jednym z wymiarów, jesteśmy w stanie ją postarzeć lub odmłodzić, nie zatracając cech charakterystycznych.
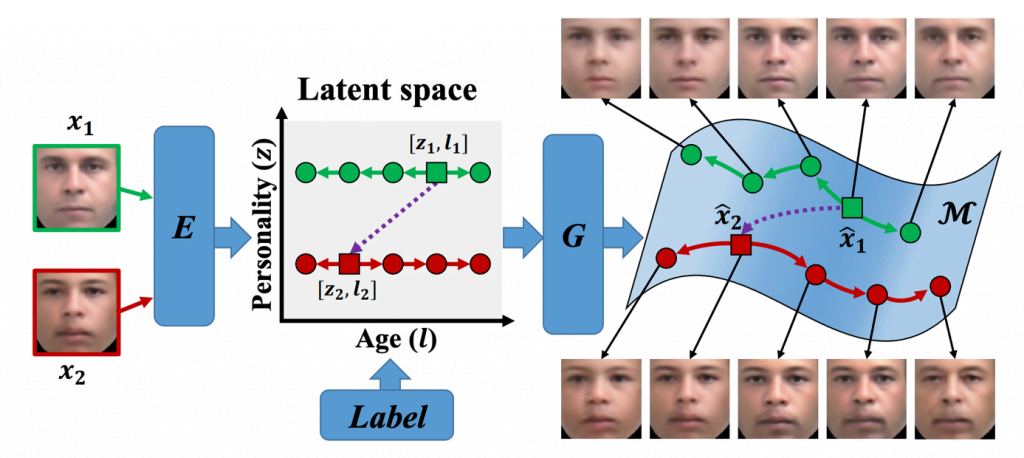
Sama sieć CAAE składa się z dwóch dyskryminatorów, które zapewniają bardzo realistyczny i akceptowalny wygląd twarzy w danym wieku.
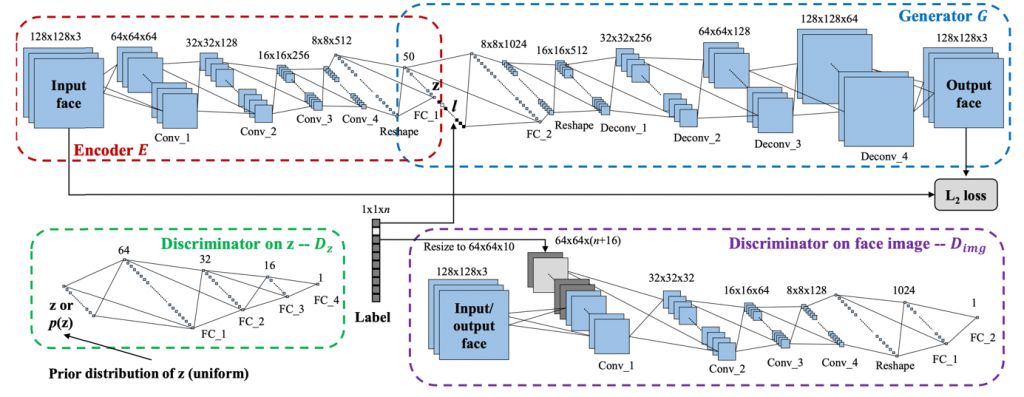
Conditional Adversarial Autoencoder – jak działa?
Enkoder E odwzorowuje obraz twarzy na wektor z (osobowość). Dodając etykietę l (wiek) do wektora z, tworzy nowy utajony wektor [z,l], który jest podawany jako wejście do generatora G.
Zarówno enkoder jak i generator są aktualizowane na podstawie straty L2 pomiędzy twarzą wyjściową a wejściową. Dyskryminator Dz narzuca równomierny rozkład na z, natomiast dyskryminator Dimg wymusza, aby twarz wyjściowa była fotorealistyczna i wiarygodna dla danej etykiety wieku. Pełen opis tego mechanizmu oraz pracę naukową opisującą go można znaleźć tutaj.
Technologia CAAE pozwala na bardzo realistyczne przewidywanie wyglądu twarzy w danym punkcie czasu (wieku). Daje nam to szerokie zastosowanie w różnego rodzaju systemach identyfikacji osób, rozrywce, czy marketingu.
Generowanie zdjęć z opisu słownego
Kolejną ciekawostką, o której chciałem opowiedzieć, jest możliwość generowania obrazów za pomocą słownego opisu tego, co ma się na nich znajdować.
W 2016 r. Han Zhang, w jednej z prac badawczych o nazwie StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks zaprezentował koncept wykorzystania technologii GAN do tworzenia zdjęć na podstawie opisu tekstowego. Tę odmianę technologii nazywamy Stacked Generative Adversarial Networks (StackGAN).
Sieci StackGAN są w stanie wygenerować fotorealistyczne obrazy w rozdzielczości 256 x 256 pikseli, które są uwarunkowane opisami tekstowymi. Ten złożony proces dzieli się na dwa etapy:

Stage-I GAN (górna część schematu) szkicuje prymitywny kształt i kolory obiektu na podstawie podanego opisu tekstowego, uzyskując obrazy o niskiej rozdzielczości.
Sieć generatywna drugiego etapu (Stage-II GAN) bierze jako wejście obraz wytworzony w etapie pierwszym oraz opis tekstowy i generuje zdjęcie o wysokiej rozdzielczości, z realistycznymi detalami. Dodatkowo jest ona w stanie usunąć różnego rodzaju wady powstałe na pierwszym etapie oraz dodać drobne lecz istotne szczegóły do zdjęcia.
A tak wygląda próbka możliwości tego mechanizmu w praktyce:

Przewidywanie wideo
Ostatnio dodatkowo zastanawiałem się nad możliwością wykorzystania GAN w kinematografii. Wyobraźmy sobie podejście, w którym całe filmy generowane są za pomocą mechanizmów AI i dostarczane nam w czasie rzeczywistym. Dostajemy kino stworzone specjalnie dla nas, z odpowiednim dopasowaniem do naszego gustu. Postacie tam występujące są w stanie robić niesamowite rzeczy, bez potrzeby wykorzystywania tzw. efektów specjalnych.
Prace nad tym tematem powoli się rozpoczynają. Carl Vondrick w swojej pracy z 2016 roku zatytułowanej Generating Videos with Scene Dynamics stworzył mechanizm pozwalający z dużą dokładnością generować kolejne klatki w filmie, przewidując kolejną sekundę filmu.

W modelu tym została zastosowana sieć GAN z przestrzenno-czasową architekturą splotową, która pozwoliła na rozdzielenie tła od pierwszego planu.
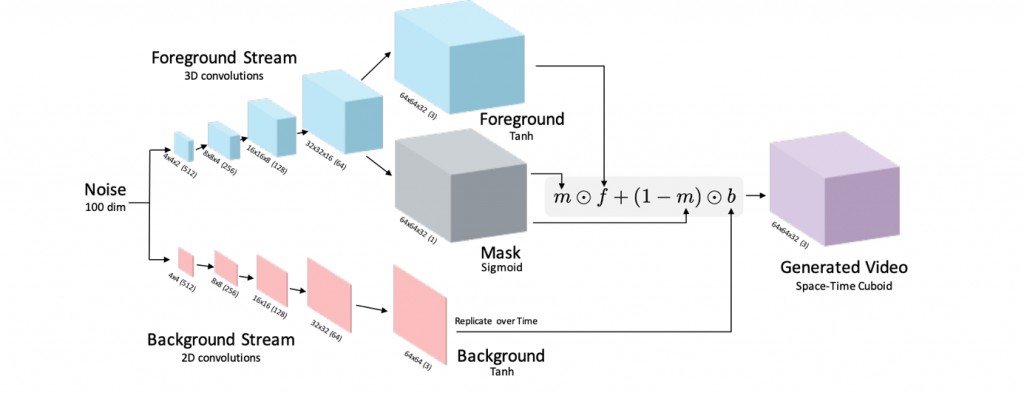
Technologia ta wymaga jeszcze udoskonalenia, natomiast już teraz jesteśmy w stanie ocenić, jakie możliwości za sobą niesie.
Możliwe zaawansowane zastosowania GAN w przyszłości
GAN daje nam naprawdę duże możliwości zastosowania w przyszłości. Dzięki niej będziemy mogli skrócić wiele procesów w dziedzinie rozrywki, projektowania maszyn lub budowli, czy nawet zwykłych zakupów lub reklamy. Oto kilka scenariuszy.
Rozrywka
Uruchamiamy Netflixa, a tam pojawiają się treści generowane specjalnie dla nas. Wszelkie scenerie i aktorzy występujący w filmach tak naprawdę nie istnieją, jednak są tak realistyczne, że nie jesteśmy w stanie tego stwierdzić. Wysokie odwzorowanie rzeczywistości pozwala postaciom posiadać zdolności i wykonywać czynności, które do tej pory nie były osiągalne dla aktorów i wymagały dużych nakładów efektów specjalnych.
Takie podejście spowoduje podniesienie odczucia realności praktycznie każdej sceny w filmie, jednocześnie obniżając czas i koszt produkcji. Idąc dalej, w momencie gdy taki mechanizm nauczy się naszych predyspozycji i gustów, będzie w stanie generować na bieżąco niesamowite produkcje, którymi będziemy się zachwycać.
Architektura i wystrój wnętrz
Drugi przykład to wykorzystanie GAN w pracach inżynierskich/architektonicznych. Wyobraźmy sobie kilka zastosowań w codziennym życiu. Na przykład chcemy zaprojektować wygląd naszego mieszkania lub odpowiednio je udekorować.
Uruchamiamy zatem aplikację mobilną, która monitoruje nasze mieszkanie za pomocą obiektywu naszego smartfona. Następnie wybieramy styl, w jakim chcielibyśmy je urządzić. Wtedy nasz mechanizm generuje w trybie rzeczywistym podgląd pokazujący, jak mógłby wyglądać projekt. Przy okazji dostajemy od niego listę mebli i wyposażenia wykorzystanego w projekcie, a także kosztorys oraz listę sklepów, gdzie można kupić wszystkie elementy.
Podobnie w budownictwie technologię tę można wykorzystać do generowania planów i wizualizacji budynków w danym miejscu dużo szybciej i dokładniej niż w przypadku prac ludzkich.
E-commerce
Cały dział e-commerce może także mocno zyskać na rozwoju sieci GAN. Wyobraźmy sobie sklep online z ciuchami. Wrzucamy tam swoje zdjęcie zrobione telefonem i możemy zobaczyć, jak będziemy wyglądali w różnych ubraniach, nie przymierzając ich w rzeczywistości. Pozwoli to dużo szybciej i łatwiej podjąć decyzję dotyczącą zakupu (niektóre sklepy już wdrażają takie rozwiązania).
Modelowanie, projektowanie 3D
Podobnie możemy skorzystać z technologii, stosując ją w różnego rodzaju modelowaniu i projektowaniu mechanicznym. Wszystkie procesy wymagające teraz ręcznego tworzenia i projektowania różnych mechanizmów mogą zostać zautomatyzowane z wykorzystaniem generatywnych modeli. W połączeniu z technologią druku 3D będziemy mogli stworzyć w pełni autonomiczny system projektowania i produkcji różnych przedmiotów i urządzeń. Przechodzimy np. do takiego systemu, opisujemy słownie, czego potrzebujemy, a mechanizm zaczyna generować nam opisywany przedmiot.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.