8 Kroków Do Wdrożenia Aplikacji W Amazon Web Services


Witajcie w pierwszej części krótkiej serii na temat wdrożenia w chmurze AWS. W niniejszym artykule opiszę jeden ze znanych mi sposobów na automatyczny deployment aplikacji w grupie auto skalowalnej, jak również poza nią.
Na potrzeby tekstu, zakładam że mamy już działającą przynajmniej jedną instancję EC2 wraz z grupą auto skalowalną i odpowiednim launch configiem. Na komputerze roboczym również posiadamy system z rodziny *nix (Linux, OS X, BSD, itp)
Plan jest taki:
- Korzystamy z repozytorium systemu kontroli wersji GIT
- Gałąź master posłuży nam jako wersja przeznaczona na produkcję
- Na produkcji korzystamy z serwera www (nginx), dzięki któremu będziemy serwować naszą “skomplikowaną” aplikację w postaci index.html z kilkoma “fajerwerkami”
- Całość będziemy przechowywać w buckecie na S3, z którego nasze instancje EC2 będą pobierać archiwum plików
Opisywany sposób wymaga użycia systemu Linux, zatem wykorzystam dystrybucję Ubuntu w wersji 14.04 LTS:
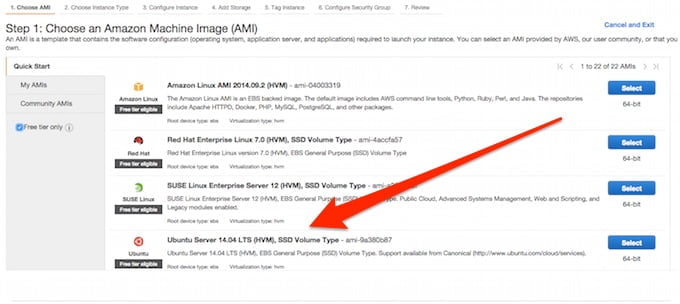
Krok Pierwszy
Tworzymy bucket S3, w którym będziemy trzymać aplikacje gotowe do wrzucenia na produkcję:
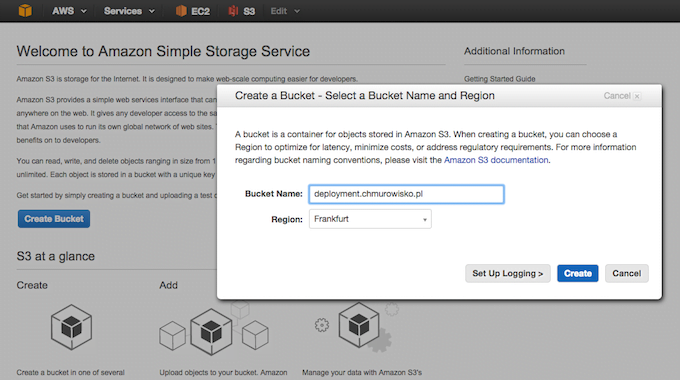
Trzeba pamiętać o tym, że przestrzeń nazw dla bucketów jest współdzielona między użytkownikami, dlatego też polecam stosowanie konwencji domenowej np: deployment.chmurowisko.pl. Nie musimy się martwić katalogiem projektu, zostanie on utworzony automatycznie podczas wysyłania plików.
Krok Drugi
Z menu w prawym górnym rogu ekranu (nazwa naszego użytkownika) wybieramy “Security Credentials”:

Następnie przechodzimy do sekcji Access Keys, gdzie tworzymy nowy klucz:

Uwaga: Istotnym jest aby odczytać/pobrać klucz zaraz po utworzeniu, gdyż po zakończeniu tego procesu nie będzie możliwości ponownego zobaczenia jego tajnej części! W razie zamknięcia okna, najlepiej usunąć klucz i wygenerować nowy.
Bezpieczeństwo: W powyższych krokach założyłem, że nie korzystamy z kont dostępowych z wykorzystaniem IAM i tworzymy klucze dla głównego użytkownika konta AWS, który posiada wszystkie uprawnienia. Najbezpieczniej byłoby utworzyć dedykowanych użytkowników i określić dla nich konkretny poziom uprawnień do S3.
Krok Trzeci
Logujemy się na serwer i instalujemy pakiet AWS CLI:
$ sudo apt-get install python-pip $ sudo pip install awscli
Na lokalnym komputerze powtarzamy czynność:
$ sudo pip install awscli
Klient AWS posłuży nam do wysyłania i pobierania danych z S3 z wykorzystaniem kluczy dostępowych. Powinniśmy teraz utworzyć konfigurację programu. W tym celu możemy skorzystać z wbudowanego konfiguratora.
Na EC2 (na potrzeby tego artykułu konfigurację utworzymy dla użytkownika root) uruchamiamy:
$ sudo -i # aws configure
Na komputerze lokalnym:
$ aws configure
Podajemy kolejno klucz dostępowy oraz klucz tajny. Następie odpowiedni region, zależnie od tego w którym posiadamy usługi oraz format, który może pozostać “None”.
Informacja: Listę regionów dla S3 znajdziesz tutaj
Program utworzy konfigurację w domyślnym katalogu użytkownika:
~/.aws/
Informacja: Dlaczego root na EC2? Dlatego, że w systemie może wszystko a na tym właśnie opiera się koncepcja deploymentu, który musi mieć dostęp do plików i katalogów, nadać im odpowiednie prawa, uruchomić/zrestartować określone usługi.
Aby przetestować poprawność konfiguracji możemy wylistować zwartość naszego S3:
$ aws s3 ls 2015-02-15 10:41:57 deployment.chmurowisko.pl
Więcej o korzystaniu z S3 w AWS CLI znajdziesz tutaj.
Krok Czwarty
Teraz, gdy już mamy działającego klienta S3 na serwerze i lokalnym komputerze, możemy przystąpić do napisania skryptów obsługujących deployment. Potrzebujemy ich do synchronizacji danych z bucketem oraz do konfiguracji aplikacji gdy uruchamia się nowy serwer w naszej grupie auto skalowalnej. Oto link do repozytorium GitHub.
Znajdziesz tam konfigurację serwera nginx, prostą stronę WWW, źródła skryptów do obsługi S3 jak również skrypt instalacyjny. Zapraszam do zapoznania się z zawartością. Pliki powłoki zawierają komentarze opisujące wykonywane czynności.
Uwaga: Konfiguracja nginx, którą zastosowałem, zakłada że nie posiadamy drugiego domyślnego serwera wirtualnego dla wpólnego interfejsu. Przyjrzyj się Twojej konfiguracji i dostosuj ją odpowiednio. W przypadku, gdy posiadasz świeżą instalację nginx usuń dowiązanie symboliczne do domyślnego pliku:
$ sudo rm -f /etc/nginx/sites-enabled/default
Krok Piąty
Aby zainstalować nasz projekt i uruchomić aplikację potrzebujemy dokonać odpowiedniej konfiguracji instancji, tak aby podczas staru systemu automatycznie uruchomił się proces deploymentu. Jednym ze sposobów jest dopisanie paru linijek do pliku:
/etc/rc.local
Jest on uruchamiany na końcu procesu boot’owania systemu Linux. Oto jego zawartość (znajdziesz ją również w repozytorium):
#!/bin/sh -e # ustawiamy srodowisko dla powloki - konieczne ze wzgledu na sciezki dostepu . /etc/environment # pobieramy setup aws s3 cp s3://deployment.chmurowisko.pl/projekt1/setup.sh /tmp sh /tmp/setup.sh
Skrypt zostanie uruchomiony z prawami użytkownika root, pobierze skrypt setup.sh i go wykona. Setup ściągnie archiwum aplikacji, rozpakuje je, utworzy odpowiednie katalogi, nada uprawnienia, utworzy dowiązania symboliczne do najnowszej wersji projektu i wstawi informacje o instancji do wybranych plików.
Plik /etc/rc.local należy zmodyfikować bezpośrednio na instancji EC2, ponieważ za chwilę utworzymy obraz (AMI) serwera. Skrypt wykona się za każdym razem gdy maszyna będzie startować, czy to dzięki polityce skalowania, czy też ręcznie w konsekwencji naszych działań.
Krok Szósty
Utworzymy teraz obraz naszej instancji EC2, tak zwane AMI.
Nim jednak się tym zajmiemy, upewnijmy się, że wszystko co do tej pory wykonaliśmy działa jak należy. Wykonajmy zatem, na lokalnym komputerze:
$ sh sync.sh
Po zakończeniu przesyłania, na EC2:
$ sudo service rc.local start
Rezultatem powyższego powinno być uruchomienie procesu deploymentu. Jeżeli coś poszło nie tak, to teraz mamy szansę to naprawić studiując poprzednie kroki 🙂
Aby utworzyc obraz instancji zaznaczamy ją na liście i z menu ACTION wybieramy Image -> Create image:

W oknie nazywamy odpowiednio nasz obraz i klikamy “Create image”:
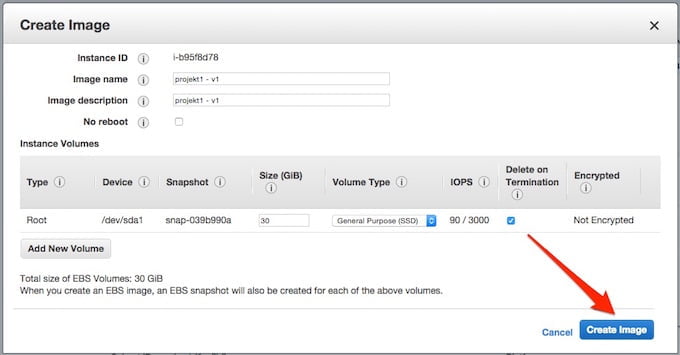
Instancja otrzyma polecenie restartu a AWS rozpocznie proces tworzenia obrazu:

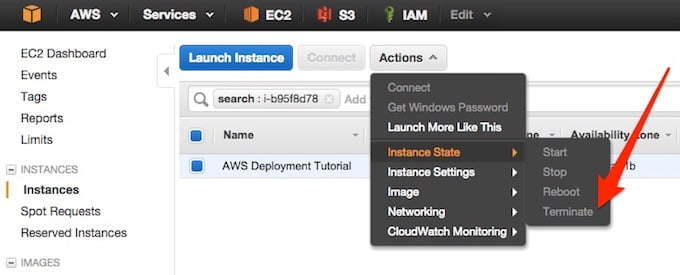
Należy uzbroić się w cierpliwość, zależnie od wielkości dysku jaki wybraliśmy może to potrwać kilka/kilkanaście minut. Proponuję aby poczekać do czasu aż obraz zostanie utworzony a następnie zterminować działanie instancji:
Możemy teraz przystąpić do utworzenia konfiguracji dla grupy auto-skalowalnej. Jako, że nasza aplikacja będzie serwować stronę WWW, schowamy ją za Load Balancerem, zatem przechodzimy do sekcji EC2 -> Load Balancers i klikamy w “Create Load Balancer”:
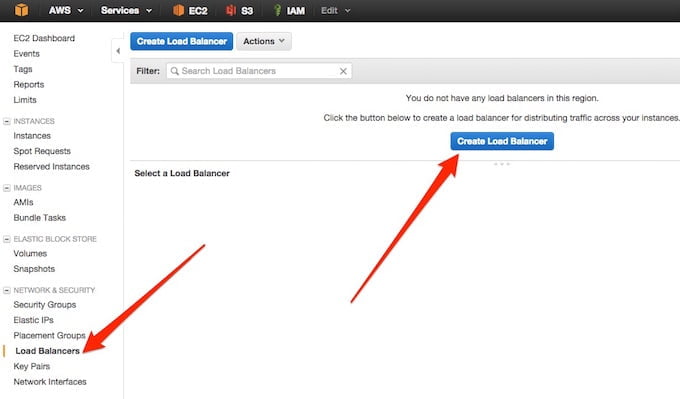
Nazywamy ELB (Elastic Load Balancer) według uznania i przechodzimy dalej:

Dalsza konfiguracja może pozostać nie zmieniona:
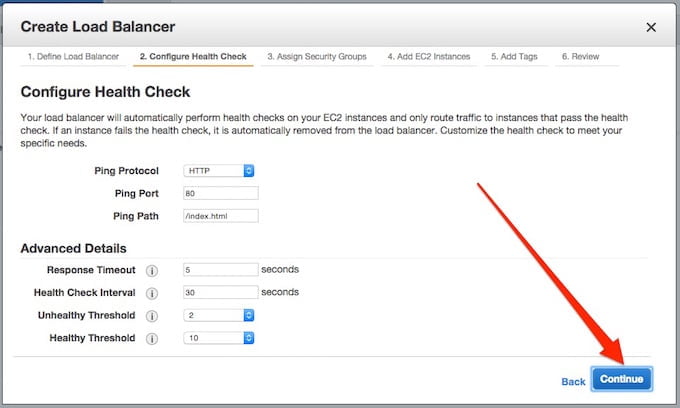
Wybieramy security grupę dla VPC/EC2 i klikamy na Continue.
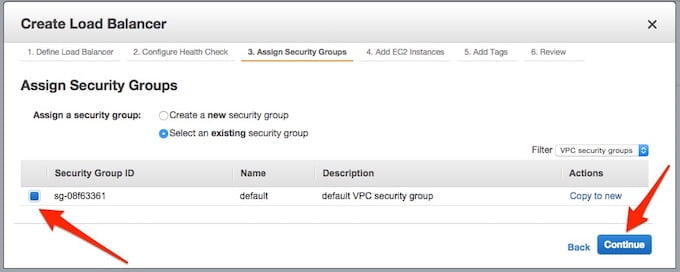
Pamiętajmy, aby security grupa umożliwiała dostęp do odpowiedniego portu dla naszych usług. W tym przypadku port 80, na który trafiać będą żądania z Load Balancera.
Na liście instancji EC2 nie dodajemy nic i przechodzimy dalej:

Możemy otagować tworzoną usługę lub pozostawić pola puste:

Na koniec powinno to wyglądać mniej więcej tak:
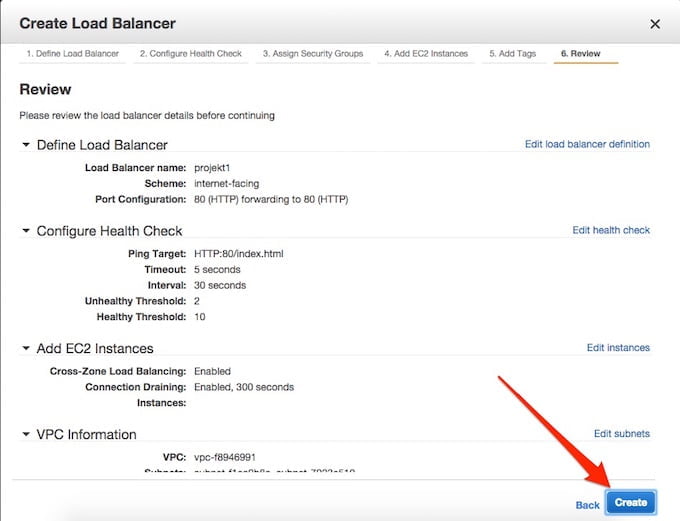
Klik w “Create” i nasz Load Balancer powstaje do życia. Kliknijmy teraz na jego nazwę i skopiujmy do schowka wartość “DNS Name”:

Krok Siódmy
Do poprawnego działania grupy auto-skalowalnej potrzebna jest konfiguracja uruchomieniowa. Przejdźmy więc do jej utworzenia:
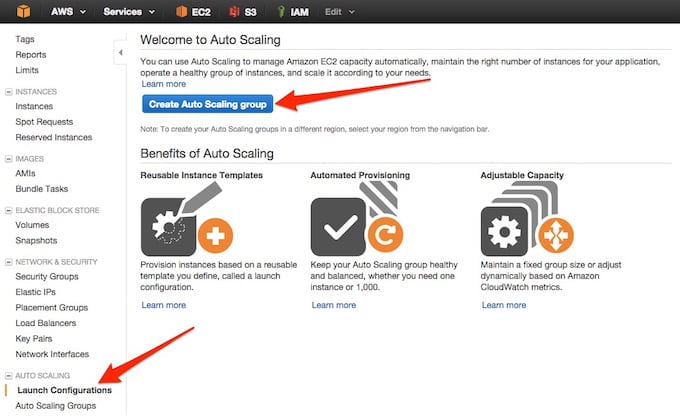
Po zapoznaniu się z procesem klikamy dalej:
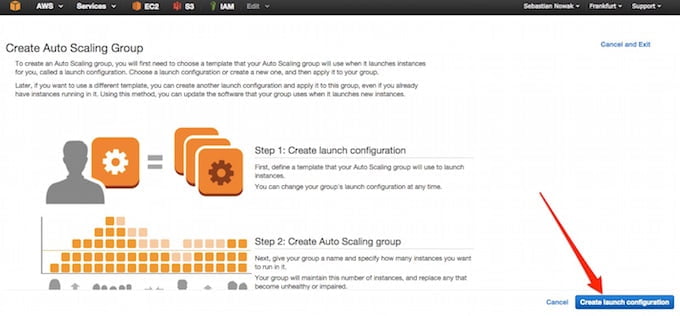
Z listy dostępnych AMI wybieramy własne i nasz świeży obaz:

Następnie decydujemy się na rodzaj instancji, tutaj wykrzystam darmową instancję t2.micro:

Po raz kolejny nazywamy usługę po naszemu i przechodzimy dalej:
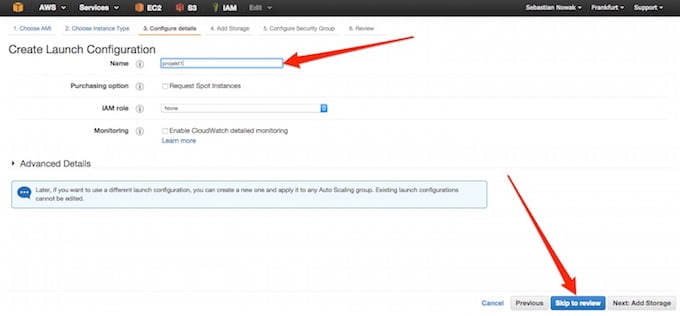
Zależnie od potrzeb ustalamy wielkość dysku dla serwera, ja zostawiłem maksymalne dla darmowej instancji 30GB:

Teraz istotna rzecz, wybór grupy bezpieczeństwa oraz upewnienie się, że port 80 jest dostępny dla wszystkich lub przynajmniej dla Load Balancera:

Na koniec ukaże się widok podsumowania, gdzie możemy przejrzeć wszystkie ustawienia i nacisnąć “Create launch configuration”.
Dodatkowo pojawi się okno z potwierdzeniem wyboru klucza SSH:
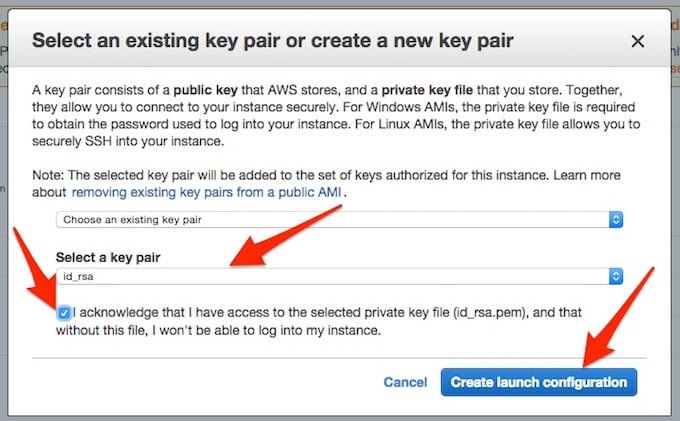
Krok Ósmy
Po zakończeniu tworzenia konfiguracji uruchomieniowej automatycznie pojawi się kreator ustawień skalowania. Nazywamy grupę po swojemu, wybieramy podsieci VPC (o ile korzystamy), rozwijamy zakładkę “Advanced Details” gdzie włączamy obsługę Load Balancera, wybieramy uprzednio utworzonego i korzystami z opcji “monitorowania zdrowia” na podstawie danych z EC2:
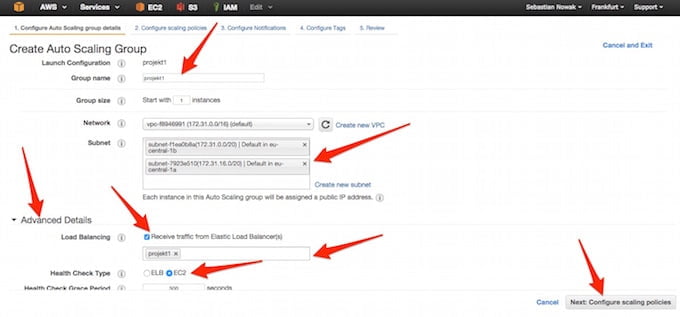
Nie będziemy zajmować się teraz sposobami na zarządzanie skalowaniem, więc na następnym ekranie zostawiamy domyślne zaznaczenie i klikamy “Review”, poczym na ekranie podsumowania wybieramy “Create Auto Scaling group”
Potwierdzenie utworzenia grupy pozwoli nam dostać sie do ich listy:

Na liście grup powinniśmy po chwili zobaczyć zmianę dotyczącą ilości uruchomionych instancji EC2 dla wybranej konfiguracji:

Przejdźmy do listy ELB i sprawdźmy co się tam dzieje:

Jak widać powstała jedna instancja, została przypięta do Load Balancera, przeszła pomyślnie kontrolę stanu zdrowia i jest gotowa do pracy. Teraz możemy skorzystać ze schowka, do którego skopiowaliśmy adres hosta ELB. Otwórzmy nowe okno przeglądarki i sprawdźmy czy działa:

Zgodnie z opisem w źródle sprawdzmy czy ID instancji zgadza się z faktycznym:


Dodatkowo zobaczmy jaki nagłówek zwraca nginx:
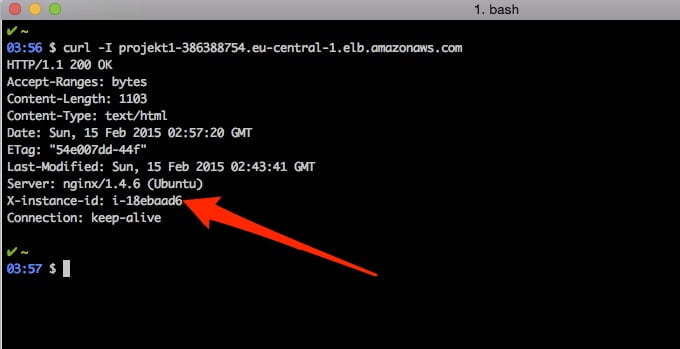
Wszystko się zgadza? Gratulacje!
No dobrze, jak teraz sprawdzić co wydarzy się w przypadku skalowania? Najprościej będzie gdy wyedytujemy maksymalną liczbę instancji w konfiguracji grupy auto-skalowalnej:

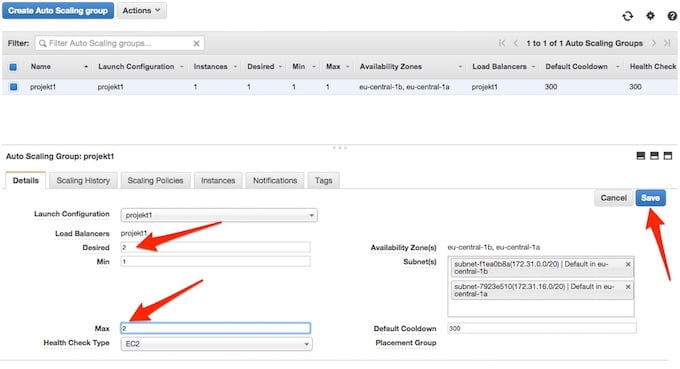
Po wybraniu “Save” i kilku sekundach powinna pojawić się dodatkowa instancja w naszej grupie i zostać, podobnie jak pierwsza, przypięta do ELB:

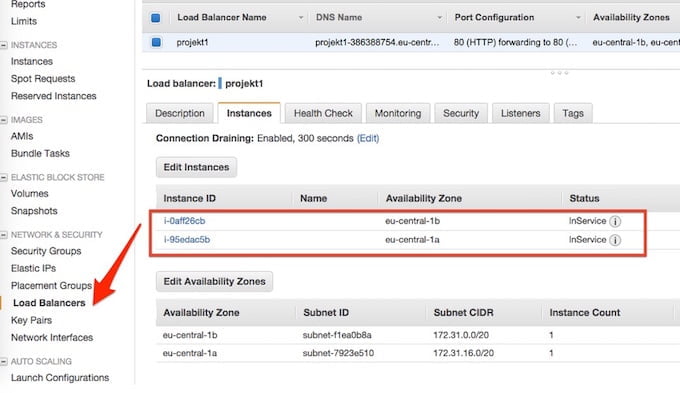
Od teraz gdy będziemy odświeżać stronę aplikacji powinniśmy zauważyć zmieniające się dane zależnie, na którą z instancji trafimy:
 Powyższy opis stanowi zlepek praktycznych doświadczeń podczas pracy z AWS oraz lektury.
Powyższy opis stanowi zlepek praktycznych doświadczeń podczas pracy z AWS oraz lektury.
Więcej na temat rozwiązań stosowanych w chmurze AWS możecie poczytać w powiązanych artykułach w powyższym serwisie.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.