Serverless Ciąg Dalszy – Bezpośredni Dostęp do DynamoDB z API Gateway


Coraz częściej przyglądamy się w Chmurowisku tematowi serverless. Nic dziwnego, mówi o nim cały świat. Wiele osób kojarzy ten termin z takimi usługami jak AWS Lambda czy Azure Functions.
Tymczasem serverless to nie tylko usługi FaaS. To „sposób myślenia” i masa innych usług, z których możemy korzystać w chmurach bez konieczności konfigurowania, zarządzania i dbania o infrastrukturę, która jest pod spodem.
W dzisiejszym artykule pokażę, w jaki sposób zapisać i odczytać dane z DynamoDB bezpośrednio przy pomocy API Gateway, bez udziału funkcji Lambda. Samo API Gateway może też służyć jako brama dla wielu innych usług w AWS.
API Gateway i DynamoDB – nasz scenariusz
Zacznijmy od omówienia scenariusza. Powiedzmy, że tworzymy jakąś aplikację i potrzebujemy miejsca, w którym możemy zapisać informacje na temat jej działania. Mogą to być zarówno wyjątki z naszej aplikacji, jak i komentarze od użytkowników.
Wysyłając dane do AWS, skorzystamy z usługi API Gateway, która może działać między innymi jako proxy do innych zasobów w AWS. Do wysyłki danych użyjemy API REST, a metoda, która dostarczy je do DynamoDB będzie wyglądała następująco:
Resource: /issue
HTTP Method: POST
HTTP Request Body:
{
"applicationId": "applicationId",
"userName": "Przemek",
"issue": "Example exception."
}
W dalszej części przykładu stworzymy także metodę GET, która zwróci do klienta dane zapisane w DynamoDB:
Resource: /issue/{applicationId}
HTTP Method: GET
Krok 1. Utworzenie tabeli w DynamoDB
W pierwszym kroku utworzymy w usłudze DynamoDB tabelę, w której będziemy przechowywali dane. Nazwa tabeli nie jest istotna. Moja nazywa się app_issues.
Jako Primary key zastosujemy exception_id, którego typ to String. Resztę parametrów możemy zostawić bez zmian.
Klikamy [Create] i czekamy, aż tabela zostanie utworzona.

Chcemy mieć możliwość pobrania danych dla konkretnej aplikacji, musimy więc stworzyć indeks dla application_id.
Aby to zrobić, po utworzeniu tabeli przez AWS przechodzimy do zakładki Indexes i tworzymy nowy indeks dla Primary key application_id. Wpisujemy nazwę indeksu, ja wybrałem application_id-index, a resztę atrybutów możemy pozostawić bez zmian.

Krok 2. Konfiguracja API Gateway
W kolejnym kroku przygotujemy nasze punkty dostępowe w usłudze API Gateway.
Zanim zaczniemy, musimy utworzyć rolę, która umożliwi sięganie do zapisów w tabeli DynamoDB. Dla uproszczenia możemy utworzyć rolę z podpiętą polityką AmazonDynamoDBFullAccess. Warto dodać także politykę AmazonAPIGatewayPushToCloudWatchLogs. Umożliwi ona zapis logów do usługi CloudWatch.
UWAGA! Po utworzeniu roli zapisujemy jej ARN, przyda nam się za chwilę.

Teraz możemy przejść do samej usługi API Gateway i utworzyć nowe API, z ustawieniami jak poniżej. Wystarczy nam API z punktami dostępowymi typu Regional.

Następnie tworzymy w naszym API nowy zasób. Nazwiemy go issue.

Konfiguracja API Gateway jest gotowa. Możemy iść dalej.
Krok 3. Tworzenie metody POST
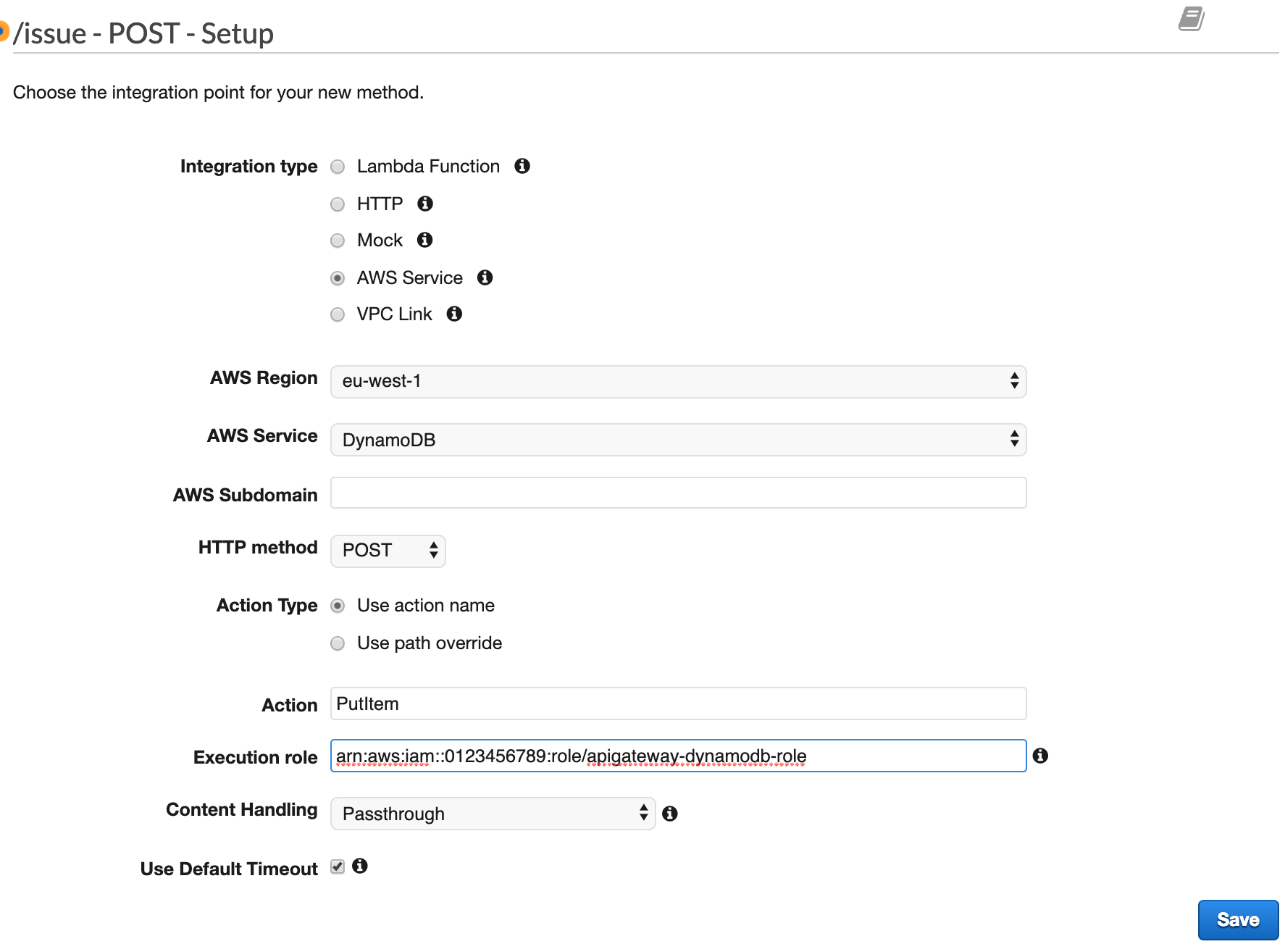
Teraz możemy przygotować metodę do wysyłania danych do naszej tabeli w DynamoDB. W tym celu w naszym zasobie tworzymy metodę POST. Musimy ją także skonfigurować:
- Wybieramy AWS Service jako Integration type.
- Jako region wybieramy ten, w którym mamy naszą tabelę DynamoDB.
- AWS Service to oczywiście DynamoDB.
- HTTP Method ustawiamy na POST.
- W pole Action wpisujemy PutItem, czyli metodę, która będzie zapisywała na naszej tabeli dane.
- Execution role to ARN roli, którą utworzyliśmy wcześniej.
Resztę ponownie pozostawiamy bez zmian i klikamy [Save]:
Krok 4. Zmieniamy format danych w zapytaniu
Mamy już naszą metodę. Musimy jednak jakoś zmienić format danych otrzymywanych od użytkownika, czyli coś takiego:
{
"applicationId": "applicationId",
"userName": "Przemek",
"issue": "Example exception."
}
zamienić na format, który zrozumie DynamoDB.
W tym celu użyjemy tak zwanego mapowania. Wybieramy metodę, klikamy w [Integration request] i rozwijamy sekcję Mapping templates. Dodajemy nowy szablon Mapping template. Jako Content Type wpisujemy application/json.

Poniżej, w polu edycyjnym, wklejamy następujący kawałek kodu napisanego w VTL. Musimy oczywiście pamiętać o wpisaniu nazwy swojej tabeli DynamoDB. Jako exception_id, czyli nasz Primary Key wykorzystamy requestId.
{
"TableName": "<YOUR TABLE NAME>",
"Item": {
"exception_id": {
"S": "$context.requestId"
},
"application_id": {
"S": "$input.path('$.applicationId')"
},
"user_name": {
"S": "$input.path('$.userName')"
},
"issue": {
"S": "$input.path('$.issue')"
}
}
}
Więcej o tym jak mapować dane w API Gateway możecie przeczytać tutaj.
Krok 5. Testujemy metodę POST
Możemy teraz przetestować naszą metodę POST i sprawdzić, czy przesłane dane zapiszą się w DynamoDB.
W tym celu w menu Actions wybieramy Deploy API, tworzymy nowy stage i czas na wykonanie pierwszego zapytania.
A oto jak wygląda przykładowe wywołanie curl:curl -X POST https://<URL OF YOUR API>/<STAGE>/issue -H 'Content-Type: application/json' -H 'cache-control: no-cache' -d '{ "applicationId": "your-application-id", "userName": "AWS User", "issue": "I love this blog post" }'
Do wysłania zapytania możemy oczywiście użyć dowolnego narzędzia.
W tym momencie w naszej tabeli powinien pojawić się pierwszy wpis. Sprawdźmy:

Możemy wykonać jeszcze kilka zapytań z różnymi applicationId. Będziemy mieli więcej danych dla metody.
Krok 6. Tworzymy metodę GET
Wracamy do usługi API Gateway. Wybieramy nasz zasób i dodajemy nową metodę:
Jako nazwę wpisujemy applicationId, a jako Resource Path {applicationid}. Będzie to parametr, za pomocą którego wybierzemy konkretną aplikację:

Tworzymy teraz metodę GET. Ustawienia są podobne do poprzedniej metody POST. Zwróćmy tylko uwagę na dwie rzeczy:
- Jako HTTP method ponownie wybieramy POST.
- Jako Action – tym razem QUERY.

Krok 7. Dodajemy mapowanie w GET
Ponownie musimy dodać mapowanie, aby przedstawić dane w formacie zrozumiałym dla DynamoDB. Jednak tym razem musimy dostosować nie tylko format dla wejścia, ale także dla wyjścia.
W tym celu zamienimy dane otrzymane z DynamoDB na JSON-a, którego zwrócimy dla użytkownika. Klikamy więc w [Integration Response] i dodajemy mapowanie tak samo jak w poprzedniej metodzie. Teraz wykorzystujemy jednak poniższy kod:
#set($inputRoot = $input.path('

Aby zmapować dane otrzymane w zapytaniu, klikamy w [Integration request], włączamy mapowanie i wklejamy poniższy kod:
{
"TableName": "<YOUR TABLE NAME>",
"IndexName": "<YOUR-INDEX-NAME>",
"KeyConditionExpression": "application_id = :v1",
"ExpressionAttributeValues": {
":v1": {
"S": "$input.params('applicationid')"
}
}
}
Należy oczywiście pamiętać o uzupełnieniu nazwy tabeli oraz stworzonego wcześniej indeksu w DynamoDB:

Krok 8. Testujemy metodę GET
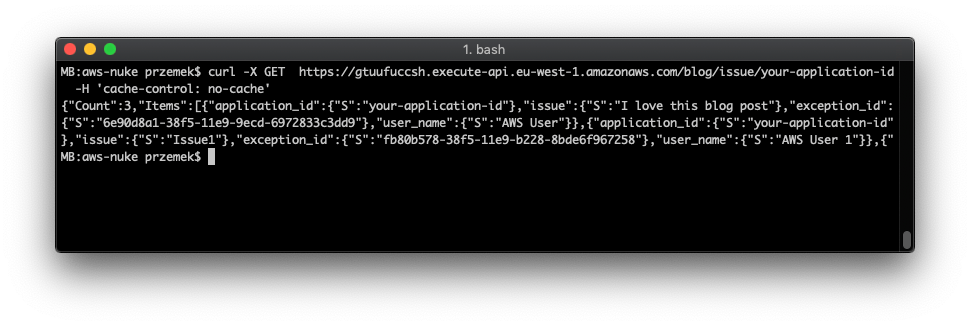
Na koniec zapisujemy wszystkie zmiany, robimy deployment API i testujemy metodę GET.curl -X GET https://<URL OF YOUR API>/<STAGE>/issue/<your-application-id> -H 'cache-control: no-cache'
Musimy pamiętać o podmianie URL-a do API oraz o wstawieniu do niego własnego identyfikatora aplikacji. W naszym przykładzie wygląda to następująco:curl -X GET https://gtuufuccsh.execute-api.eu-west-1.amazonaws.com/blog/issue/your-application-id -H 'cache-control: no-cache'
Jeżeli wykonaliśmy wszystko poprawnie, rezultat powinien być podobny do poniższego:
Metodę GET możemy zresztą przetestować w dowolnej przeglądarce:

Podsumowanie
Dzisiaj sprawdzaliśmy, w jaki sposób „podłączyć” się do DynamoDB bezpośrednio za pomocą usługi API Gateway, bez funkcji Lambda. Możliwość ta nie jest oczywiście ograniczona tylko do DynamoDB. Możemy podobnie pracować np. z S3, Kinesis, czy SNS.
Z drugiej strony należy wiedzieć, że bezpośredni dostęp do bazy danych z API Gateway nie zawsze będzie możliwy. Często potrzebujemy więcej funkcji niż tylko prosty zapis i odczyt danych. Tam, gdzie wymagana jest skomplikowana logika, takie rozwiązanie się nie sprawdzi. Jednak warto mieć je na uwadze. Powinno przyśpieszyć nasze API, a my zapłacimy mniej za usługi w Amazon Web Services.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.