Jak mikroserwisy dockerowe dogadują się w AWS


Chmura publiczna jest bardzo dobrym środowiskiem dla aplikacji opartych o mikroserwisy.
Mikroserwisy, napisane w odpowiedni sposób, mogą być w każdym momencie zastopowane, skalowane horyzontalnie, uruchamiane od nowa, w różnych miejscach, na wielu maszynach wirtualnych. A wszystko dzieje się automatycznie, bez naszego udziału.
Jak więc mikroserwisy dockerowe dogadują się w AWS? Skąd wiedzą, gdzie który jest? Gdzie wysłać request?
Chmura tasków
Jak wiecie, podstawowym elementem usługi Elastic Container Service jest Task. Task to z grubsza, uruchomiony jeden lub więcej kontenerów. Taki pod z Kubernetes. Taska można uruchomić jako Service. Service to taki „enkapsulator” dla taska. Programiści wiedzą o czym mowa 😉
Serwis trzyma taski przy życiu, udostępnia je na zewnątrz, śledzi w jakim miejscu task jest uruchomiony. Serwisy kierują także ruch na odpowiedniego node’a (maszynę wirtualną) i port. No właśnie, na odpowiedniego node’a.
W aplikacjach mamy przeważnie uruchomionych wiele serwisów, z różnymi zadaniami. Część aplikacji odpowiada na przykład za autoryzację, część za komunikację z bazami danych, a jeszcze inne obsługują bezpośrednio requesty od użytkowników.
W każdym takim serwisie może pracować wiele kontenerów, rozrzuconych po kilku node’ach naszego klastra.

Mamy więc wiele kontenerów uruchomionych na jednej maszynie wirtualnej. Każdy z nich może mieć wyeksponowany taki sam port, np. 80. Nie da się więc zmapować wszystkich tych portów (Bridge) do jednego portu na interfejsie sieciowym maszyny, na której kontenery są uruchomione. Na jednym porcie może przecież nasłuchiwać tylko jeden serwis. #jakżyć?
Dynamic Host Port Mapping
Pracując z Dockerem, możemy połączyć port w kontenerze z portem na naszym interfejsie sieciowym. Służy do tego flaga -p w komendzie docker run. Polecenie uruchomi kontener i „wystawi” jego port 3000 na porcie 80 naszej maszyny. Ale można użyć także flagi -P i wtedy port kontenera zostanie zmapowany na „losowy” port naszej karty sieciowej.
Jeżeli uruchomimy na przykład nginx-a za pomocą polecenia $ docker run -d -P nginx to jego port 80 zostanie połączony z jakimś portem na naszej maszynie. Wylistujmy sobie nasze uruchomione kontenery i…

Jak widać, nasz nginx jest udostępniony na porcie 32768. I rzeczywiście, łącząc się z tym portem otrzymamy odpowiedź z nginx.

Na bardzo podobnej zasadzie działa w AWS tak zwany Dynamic Host Port Mapping.
W każdym z serwisów pracują taski. Taski definiujemy za pomocą Task Definition, czyli dokumentu, który opisuje w jaki sposób usługa ECS ma stworzyć nasz kontener. Jedną z opcji w takiej definicji jest mapowanie portów. Przy statycznym mapowaniu nasz wpis wygląda tak:
"portMappings: [
{
"hostPort": 80,
"protocol": "tcp",
"containerPort": 80
}
],
Myślę, że zapis jest jasny. Jeżeli natomiast chcemy użyć dynamicznego mapowania portów, musimy po prostu zmapować port kontenera na port 0 naszego node’a. Czyli definicja przybierze postać:
"portMappings:
{
"hostPort": 0,
"protocol": "tcp",
"containerPort": 80
}
],
I to wszystko. Od teraz nasz klaster będzie udostępniał kontenery na wolnych portach karty sieciowej.

W jaki sposób udostępnić jednak takie serwisy naszym użytkownikom? Trudno wymagać od nich, aby sprawdzali losowe porty na naszym adresie IP.
Load Balancing
Bezpośrednie wystawianie do Internetu maszyn wirtualnych pracujących w klastrze dockerowym nie tylko nie jest dobrym pomysłem (powinny one raczej pracować w sieciach prywatnych), ale jak widać, w przypadku dynamicznego mapowanie portów, taki sposób udostępniania naszych usług nie jest za bardzo możliwy.
Tu z pomocą przyjdą nam load balancery. AWS udostępnia trzy rodzaje load balancerów. Bez wchodzenia w szczegóły do rozwiązania naszego problemu można wykorzystać Application Load Balancer. Umożliwia on między innymi tak zwany Path Based Routing, czyli kierowanie requestów przychodzących na różne ścieżki w różne miejsca docelowe, tak zwane targety.

Na schemacie widać, że load balancer kieruje requesty w odpowiednie miejsca docelowe. Skąd wie gdzie? Otóż pomiędzy load balancerami, a maszynami wirtualnymi tworzymy Target Group.
Target grupa to taki abstrakcyjny twór, który grupuje taski uruchomione w ramach jednego serwisu w grupę. Każdy task przy uruchomieniu rejestruje się automatycznie w odpowiedniej target grupie i load balancer wie, gdzie może przekierować konkretny request.
W przypadku przedstawionym na schemacie mielibyśmy trzy target grupy:
- auth,
- web,
- service.
Mamy więc załatwioną sprawę dostępu do naszej aplikacji z internetu. Jednak nie wszystkie mikroserwisy w naszych aplikacjach muszą być dostępne z sieci. Część z nich jest potrzeba tylko dla innych serwisów pracujących na potrzeby naszej aplikacji. Tutaj możemy obejść się bez load balancingu. Z pomocą przyjdzie nam…
Service Discovery
Załóżmy, że nasza aplikacja składa się z trzech mikroserwisów. Jeden z nich jest dostępny z internetu, a pozostałe dwa mają być dostępne tylko dla serwisu publicznego.
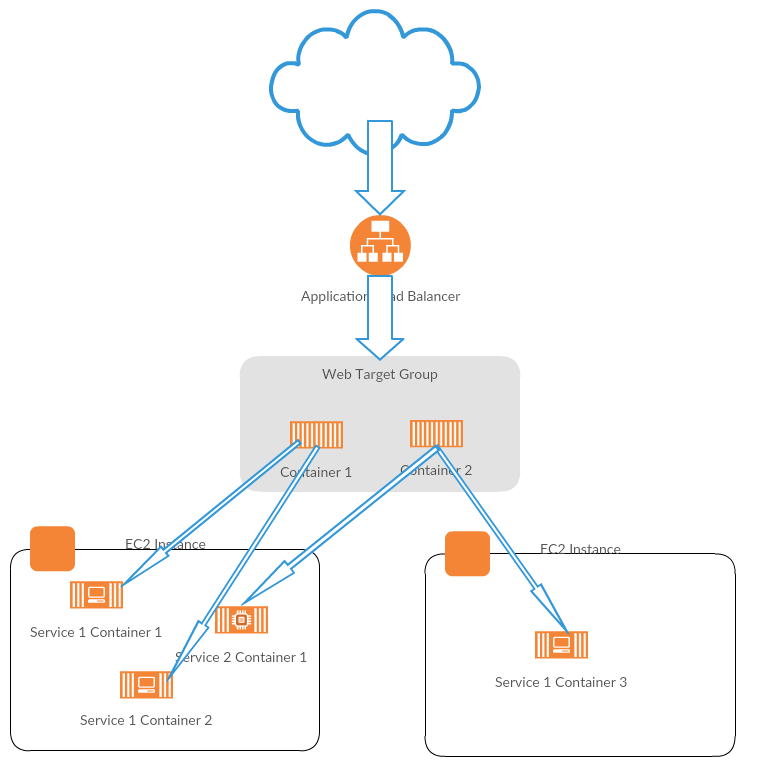
Serwis publiczny, nazwijmy go web, jest dostępny publicznie. Ale że by funkcjonował poprawnie musi mieć możliwość pobrania danych z pozostałych dwóch serwisów i zwrócić je w odpowiedzi na request.
Serwisy prywatne mogą być uruchomione na jakiejkolwiek maszynie wirtualnej wchodzącej w skład naszego klastra i nasłuchiwać na nieznanym porcie. Jak poradzić sobie w takim przypadku?
Pomoże nam w tym usługa Amazon ECS Service Discovery. Service Discovery tworzy w usłudze Route 53 tak zwane namespaces. Jest to odpowiednik Hosted Zony. Takich przestrzeni możemy mieć oczywiście wiele. Jednak każda z nich może być podpięta pod tylko jedną VPC.
W momencie kiedy klaster ECS uruchamia kolejne taski, bądź usuwa już niepotrzebne lub źle działające, automatycznie zmieniane są wpisy w odpowiedniej namespace, a nasze aplikacje mogą kontaktować się z konkretnymi serwisami za pomocą ładnych nazw przy użyciu DNS.

Jak to wygląda w praktyce?
Skonfigurowałem klaster ECS pracujący na instancjach EC2. W sumie mam 3 instancje maszyn wirtualnych, aby taski pracujące w ramach serwisów były rozrzucane w różne miejsca.

Uruchomiłem wszystkie trzy serwisy, a w każdym z nich inną ilość pracujących tasków.
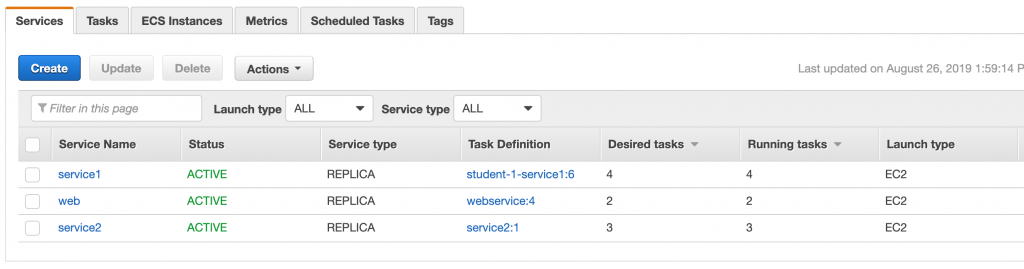
Serwis web pracuje oczywiście za load balancerem. On nie musi być rejestrowany w Service Discovery. Żaden inny task nie będzie go wywoływał.
Dla serwisów service1 i service2 stworzyłem jednak namespace w Route 53 oraz ustawiłem włączyłem dla nich integrację z Service Discovery.

Po uruchomieniu całości miałem aktywne 9 tasków, z których 7 powinno być zarejestrowane w Service Discovery.
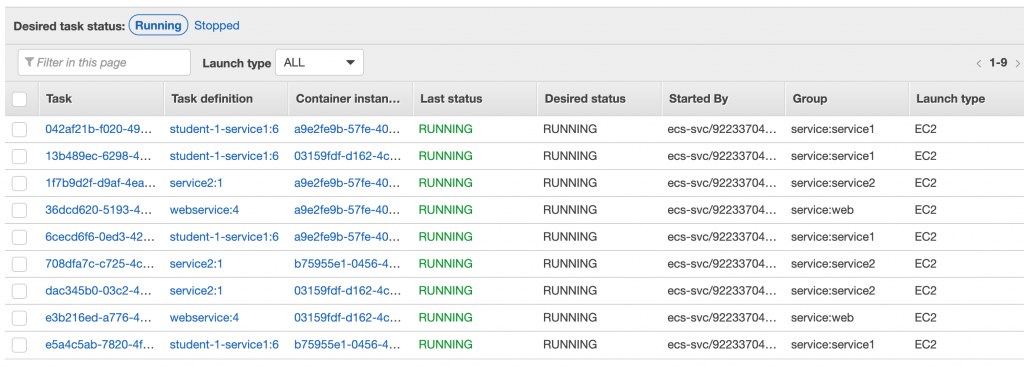
Sprawdźmy, jak to wygląda w Route53.
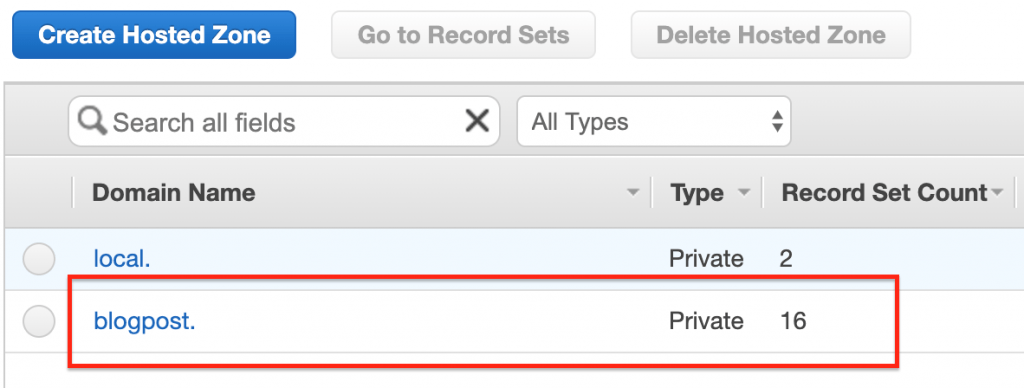
Jak widać, mamy namespace dla naszych serwisów, wewnątrz których ECS Discovery Service rejestruje instancje naszych tasków. Wygląda to następująco:
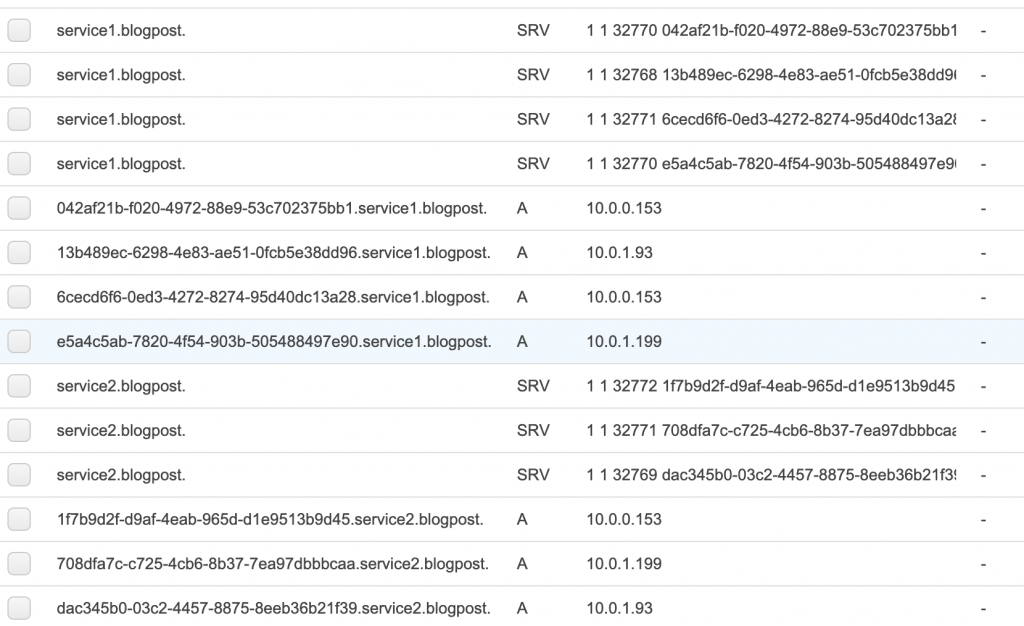
Jak widać, mamy kilka wpisów dla każdego z tasków.
Jeżeli korzystamy z kontenerów uruchamianych na EC2 dodawane są rekordy typu SRV, w których mamy zapisane zarówno nazwy hostów jak i numery portów, na których konkretny task nasłuchuje. W przypadku Fargate mielibyśmy tylko rekordy typu A, gdyż każdy z kontenerów uruchamianych na Fargate ma swój osobny interfejs sieciowy.
Aby sprawdzić czy wszystko działa, na maszynie wirtualnej uruchomionej w VPC, do której podpięta jest nasza przestrzeń nazw możemy wykonać polecenie dig , które sprawdzi nasze wpisy w DNS.
dig SRV service1.blogpost
i mamy wynik:
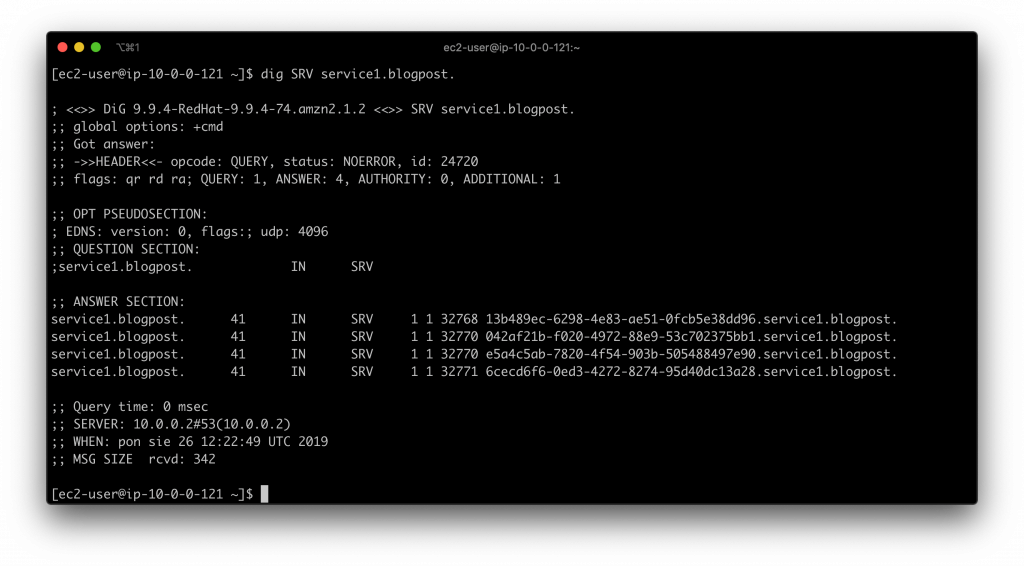
Jak widać, dostaliśmy multi-value answer, czyli wiele adresów dla jednego serwera. Wszystko jest ok. Możemy teraz wybrać jedną z wartości i poprosić DNS o adres IP konkretnego serwera:
dig 13b489ec-6298-4e83-ae51-0fcb5e38dd96.service1.blogpost
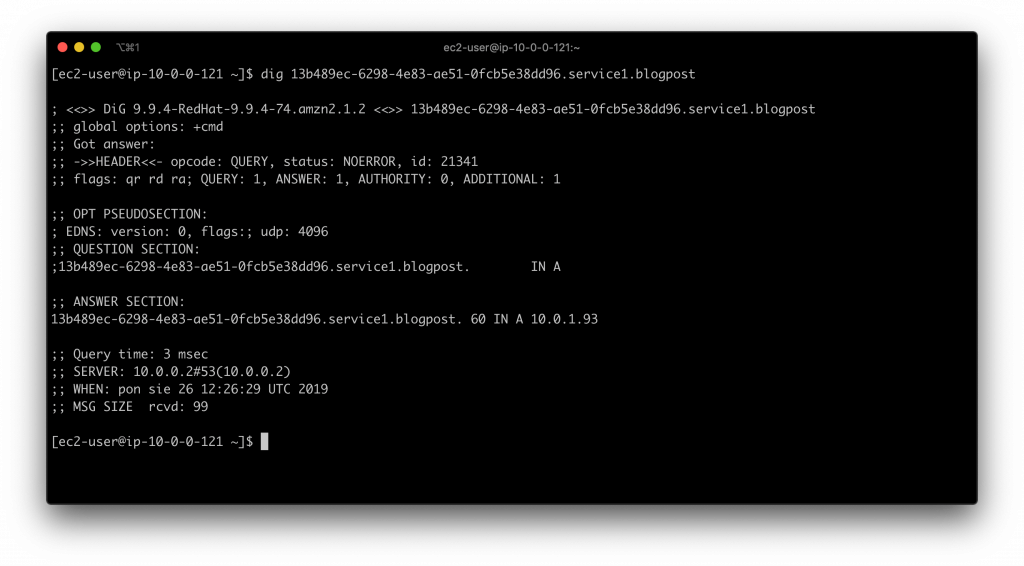
Całość widoczna jest także w serwisie AWS Cloud Map. To takie centrum dowodzenia naszymi mikroserwisami.

Można tam, poza oczywiście kontrolą tego co wyczynia Discovery Service dodawać także swoje własne serwisy oraz rejestrować w nich dodatkowe instancje mikroserwisów, czy też usuwać już niepotrzebne.
Jeżeli po ręcznym usunięciu serwisów ECS pozostaną w Route53 jakieś wpisy wykonane przed Discovery Service to także w AWS Cloud Map można je usunąć.
Podsumowanie
W artykule pokazałem w jaki sposób można skonfigurować w AWS mikroserwisy uruchamiane przy pomocy dockerów tak aby były widoczne zarówno z internetu, jak i wewnątrz prywatnych sieci.
Na pierwszy rzut oka może wydawać się to skomplikowane, ale po kilku takich deploymentach wszystko staje się jasne i bardzo proste. A naprawdę taka konfiguracja zrzuca z nas obowiązek późniejszego ręcznego konfigurowania całości. Wszystko dzieje się automatycznie.
Jeżeli macie jakieś problemy z konfiguracją środowiska mikroserwisów w AWS to oczywiście można śmiało się z nami kontaktować. Spróbujemy pomóc.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.