Jak uruchomić klaster Kubernetes w AWS na instancjach typu spot? (Znów oszczędzamy!)


Popularność Kubernetesa nieustannie rośnie. Sporo firm już go używa, a jeszcze więcej chce poznać tę technologię.
Kubernetesa najłatwiej uruchomić w chmurze, mamy tam bowiem dostępne zarządzane przez vendorów klastry. Nie musimy nic – no prawie nic – konfigurować, uaktualniać, backupować. Jednak tu pewnie pojawia się obawa o koszty. I nie będę zaprzeczał, nieumiejętne korzystanie z dobrodziejstw chmury publicznej może finansowo zaboleć.
Dlatego dzisiaj pokażę, jak postawić klaster Kubernetesa na instancjach spot i zaoszczędzić przy tym sporo pieniędzy – nawet do 90%. Zostanie więcej na lody albo kebaba 😉
EKS – Kubernetes w AWS
Można oczywiście korzystać z maszyn wirtualnych i samemu uruchomić klaster. Jest sporo narzędzi, które w tym pomogą:
Ale zostawmy to specjalistom i tym, którzy potrzebują skrojonego pod siebie klastra, wiedzą co robią i mogą poświęcić cenny czas na konfigurowanie zamiast używania.
Siła chmur to usługi zarządzane i dlatego wykorzystamy Amazon EKS. To usługa AWS, która pozwoli nam z łatwością korzystać z Kubernetesa w chmurze Amazona.
Szybki rzut oka na Kubernetesa
Kubernetes „składa się” z dwóch części, control plane i węzłów, czyli maszyn, na których uruchamiamy nasze aplikacje.

Trudno powiedzieć, która część jest ważniejsza. Obie są potrzebne. Ale usługa EKS bierze na siebie połowę odpowiedzialności i cała warstwa kontrolna, czyli wszystkie komponenty zarządzające naszym klastrem, jest zarządzana przez AWS. Ufff… Połowa zmartwień z głowy.
Dla nas zostają worker nodes, czyli miejsce, gdzie uruchamiamy nasze aplikacje. W przypadku EKS to maszyny wirtualne podzielone na grupy (node groups). I to właśnie im dziś się przyjrzymy.
P.S. Możemy także uruchamiać aplikacje bez maszyn, o czym wspominam krótko na końcu artykułu.
Jak uruchomić klaster EKS?
Można oczywiście przeklikać się przez konsolę AWS, ale my, profesjonaliści, użyjemy eksctl. To oficjalne narzędzie, które umożliwia pracę z klastrami Kubernetesa w EKS. Instrukcję jego instalacji znajdziesz tutaj. Mój tutorial zakłada, że masz już zainstalowane eksctl i kubectl.
Najprostszy sposób uruchomienia klastra to:
eksctl create cluster \ --name eks1 \ --nodegroup-name workers \ --node-type t3.medium \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami auto \ --vpc-nat-mode Disable \ --region eu-west-1
W rezultacie dostaniemy zasoby w Irlandii, lokalnie zapisze się nowy kontekst i będziemy mogli od razu rozpocząć pracę z klastrem. Dostępna będzie autoscaling group, którą można skalować w miarę potrzeby. Za mało serwerów? Dodajemy jeden lub kilka i jest dobrze. Takie tam zalety chmur. Można też oczywiście taką grupę zmniejszać wedle uznania.
Definiowanie zasobów w pliku YAML
Pracując z Kubernetesem, na pewno chcesz definiować zasoby na pomocą plików YAML. Prawda? 😉 Istnieje oczywiście taka możliwość:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: basic-cluster
region: eu-west-1
version: "1.16"
vpc:
nat:
gateway: Disable # other options: Disable, Single (default)
nodeGroups:
- name: ng-1
instanceType: t3.medium
minSize: 1
maxSize: 2
desiredCapacity: 1
Uruchamianie klastra z kubectl
Jeśli znasz kubectl, to nie zaskoczy Cię to, co teraz napiszę. Aby utworzyć klaster zdefiniowany za pomocą powyższego pliku, wykonaj polecenie:
eksctl create cluster -f [NAZWAPLIKU]
Stwórzmy więc taki klaster. Odpalamy polecenie i… czekamy kilkanaście minut.
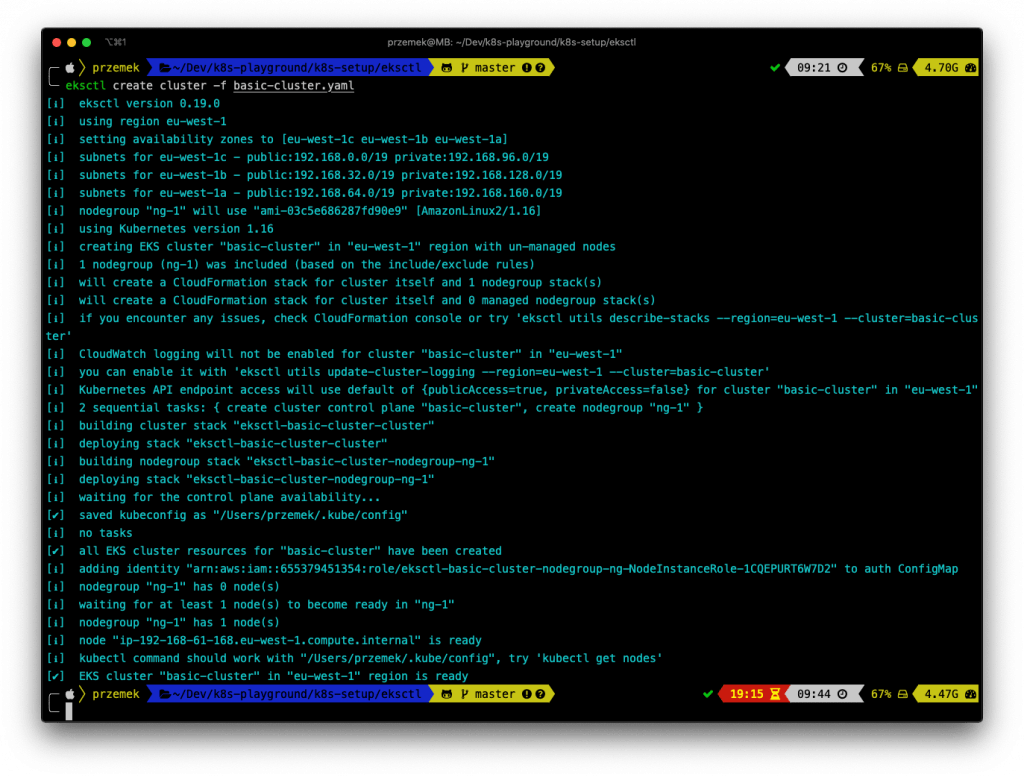
Pod spodem eksctl buduje dla nas dwa stacki, wykorzystując CloudFormation. Jeden dla klastra EKS i drugi dla grupy autoskalującej z naszymi węzłami.

Jeżeli przyjrzysz się utworzonemu klastrowi, zauważysz, że nie masz dostępnych żadnych węzłów.

Ale polecenie kubectl get nodes jednak coś zwraca:

O co chodzi? EKS pozwala na pracę zarówno z maszynami zarządzanymi przez samą usługę, jak i z maszynami pracującymi poza EKS. W naszym przypadku eksctl utworzył autoscaling group i podpiął ją pod nasz klaster.

Tę grupę można oczywiście także skalować, aby zwiększyć bądź zmniejszyć liczbę pracujących w naszym klastrze maszyn:

Managed groups
eksctl umożliwia także uruchamianie zarządzanych przez EKS grup serwerów. W tym celu wystarczy w pliku opisującym nasz klaster zamienić sekcję nodeGroups na managedNodeGroups.
Możesz też dodać kolejną grupę serwerów do swojego klastra. Definicja może wyglądać tak:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: basic-cluster
region: eu-west-1
managedNodeGroups:
– name: managed-ng
instanceType: t3.medium
minSize: 1
desiredCapacity: 1
maxSize: 1
volumeSize: 20
labels: {role: worker}
Aby „zaaplikować” taką grupę do naszego klastra, wykonujemy polecenie eksctl create nodegroup -f nodegroup.yaml.
Dosłownie po chwili grupa staje się dostępna w klastrze:

Możemy także przeglądać i usuwać istniejące grupy maszyn. Aby pobrać listę grup, należy wykonać polecenie eksctl get nodegroups --cluster=basic-cluster.

Aby usunąć grupę, wykonaj eksctl delete nodegroup --cluster=basic-cluster --name=ng-1 eksctl get nodegroups --cluster=basic-cluster.
Gdzie te spoty?
No właśnie. Miało być tanio. Na dziś za warstwę kontrolną EKS płacimy 0,10 $ za godzinę. Dużo? Mało? To zależy 🙂
Jeśli chcesz zaoszczędzić na maszynach, na których pracują aplikacje = chcesz spotów. No to dajemy!
Dodajemy same spoty
Zakładam, że klaster już masz. Dodajmy zatem nową grupę. Konfiguracja wygląda następująco:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: basic-cluster
region: eu-west-1
nodeGroups:
– name: ng-spots-1
minSize: 1
maxSize: 5
instancesDistribution:
maxPrice: 1
instanceTypes: ["c5.large", "t3.medium"]
onDemandBaseCapacity: 0
onDemandPercentageAboveBaseCapacity: 0
spotInstancePools: 2
– name: ng-spots-2
minSize: 1
maxSize: 5
instancesDistribution:
maxPrice: 1
instanceTypes: ["c5.large", "t3.medium"]
onDemandBaseCapacity: 0
onDemandPercentageAboveBaseCapacity: 0
spotInstancePools: 2
Tworzymy dwie grupy autoskalujące z instancjami spot. Dlaczego dwie? Będzie większa szansa, że maszyny nam nie znikną. Warto zajrzeć tutaj i sprawdzić, jak często dany typ maszyny jest odbierany użytkownikowi.
Jak widzisz, zarówno onDemandBaseCapacity, jak i onDemandPercentageAboveBaseCapacity są ustawione na zero.
Oznacza to, że w danej grupie będą tylko maszyny typu spot. Możesz też oczywiście w jednej grupie maszyn umieścić obok instancji spot także instancje typu on-demand.
No dobrze, pozostało tylko
wywołać eksctl create nodegroup -f spot-ng.yaml i
chwilę poczekać:

Mamy już kilka grup (eksctl get nodegroups --cluster=basic-cluster):

oraz kilka węzłów:

Możemy też usunąć grupy niespotowe:
eksctl delete nodegroup --cluster=basic-cluster --name=ng-1 eksctl delete nodegroup --cluster=basic-cluster --name=managed-ng
I po chwili mamy klaster pracujący tylko na spotach.
Klaster na instancjach spot trochę szybciej
Oczywiście te wszystkie kroki nie są niezbędne, aby otrzymać klaster na instancjach spot. Chciałem Ci pokazać więcej możliwości eksctl. Możesz od razu utworzyć taki klaster, na przykład wykorzystując poniższy plik z konfiguracją:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: basic-cluster-spot
region: eu-west-1
version: "1.16"
vpc:
nat:
gateway: Disable
nodeGroups:
– name: ng-spots-1
minSize: 2
maxSize: 2
instancesDistribution:
maxPrice: 1
instanceTypes: ["c5.large", "t3.medium"]
onDemandBaseCapacity: 0
onDemandPercentageAboveBaseCapacity: 0
spotInstancePools: 2
– name: ng-spots-2
minSize: 2
maxSize: 2
instancesDistribution:
maxPrice: 1
instanceTypes: ["c5.large", "t3.medium"]
onDemandBaseCapacity: 0
onDemandPercentageAboveBaseCapacity: 0
spotInstancePools: 2
W rezultacie dostajemy klaster z czterema węzłami w dwóch grupach:

Pamiętaj, by po wszystkim usunąć klaster za pomocą polecenia eksctl delete cluster -f basic-cluster.yaml.
A EKS bez serwerów?
Obiecałem uruchamianie aplikacji bez maszyn. Szybki sposób podaję poniżej. A jeśli szukasz bardziej szczegółowych informacji na ten temat, zajrzyj do jednego z moich poprzednich wpisów.
Możesz postawić klaster EKS bez żadnych worker nodes i nadal uruchamiać na nim swoje aplikacje. Z odsieczą przychodzi tu AWS Fargate.
Uruchomienie takiego klastra jest bardzo proste. Plik z konfiguracją wygląda następująco:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: fargate-cluster
region: eu-west-1
fargateProfiles:
– name: fp-default
selectors:
– namespace: default
– namespace: kube-system
Mamy tu tylko jeden profil, ale wszystko, co trafi do namespace default, będzie uruchomione na Fargate.
Podsumowanie
Uruchamianie i podstawowe zarządzanie klastrami EKS nie musi być skomplikowane. Mam nadzieję, że udało mi się to pokazać.
Jeśli zaczynasz przygodę z Kubernetesem, to podstawowym wymaganiem, aby nauczyć się z nim pracować, jest posiadanie klastra. Bez tego ani rusz. Warto więc przygotować sobie plik z konfiguracją i nauczyć się, jak w łatwy sposób takie klastry tworzyć i je usuwać.
Jednak interfejs eksctl potrafi o wiele więcej. Użytkowników, którzy opanowali już podstawową obsługę klastrów, zapraszam na stronę projektu. Na GitHubie dostępne są także przykładowe konfiguracje, które warto wykorzystać. A w razie jakichkolwiek pytań, jak zwykle zachęcam do kontaktu z naszym zespołem?
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.