KEDA z bliska. Kubernetes

Od ostatniej konferencji Microsoft Build 2019 minęło już całkiem sporo czasu. Część z Was być może miała okazję zapoznać się z podsumowaniem pierwszego dnia eventu w wykonaniu Michała Furmankiewicza (jeśli nie, zachęcam do wysłuchania). Michał wspomina m.in. o projekcie KEDA Kubernetes Based Event Driven Autoscaling, który wzbudził niemałe zainteresowanie osób pracujących na co dzień z Kubernetesem. W tym wpisie chciałbym się razem z Wami przyjrzeć temu rozwiązaniu nieco dokładniej.
Czym jest KEDA ?
Projekt KEDA powstał dzięki współpracy inżynierów z firm Red Hat i Microsoft. Opisywany jest jako komponent open source, który możemy zainstalować w klastrze Kubernetes, aby umożliwić skalowanie kontenerów w oparciu o zdarzenia. Jest to rozszerzenie możliwości K8S, które samo w sobie bazuje na metrykach CPU i pamięci podczas skalowania kontenerów. Projekt znajduje się w fazie eksperymentalnej, a postępy w jego rozwoju możemy śledzić na GitHubie.
KEDA posiada specjalne adaptery – komponenty, które łączą się z naszym źródłem danych w celu uzyskania metryk. Metryki te służą dalej za wyznacznik, czy i jak skalować nasze środowisko. Aktualnie przygotowanych jest siedem takich połączeń m.in. do RabbitMQ, bazy Redis, czy Azure Service Bus. Planowane są kolejne, jak np. Azure IoT Hub czy Cosmos DB.
KEDA jest zatem komponentem, który umożliwia klastrowi K8S bycie efektywną infrastrukturą dla architektury event-driven, bez potrzeby tworzenia swojego komponentu skalującego na podstawie kolejki zdarzeń.

Jak zbudowana jest KEDA?
Jak widać na powyższym wykresie, KEDA dostarcza w naszym klastrze 3 podstawowe elementy:
- Scaler – komponent łączący się ze wskazanym przez nas źródłem (np. RabbitMQ) i odczytujący jego metryki (długość kolejki).
- Metrics Adapter – element udostępniający metryki odczytane przez Scaler i przekazywane komponentowi Horizontal Pod Autoscaler (HPA), umożliwiającemu automatyczne skalowanie poziome aplikacji.
- Controller – ostatni i chyba najważniejszy element, który zapewnia skalowanie od 0 do 1 (lub od 1 do 0) dla konsumenta kontenera. Dlaczego tylko do 1 lub 0? Ponieważ całe rozwiązanie ma tylko rozszerzać możliwości Kubernetesa, a nie wymyślać niczego na nowo. Controller jedynie skaluje do pierwszej instancji, a dalszym jej klonowaniem zajmuje się już komponent HPA przy użyciu metryk z Metrics Adapter. Kolejnym zadaniem Controllera jest ciągłe śledzenie, czy nie pojawił się nowy deployment typu ScaledObject.
Tworzymy deployment ScaledObject
W celu użycia rozwiązania KEDA z naszymi kontenerami musimy przygotować deployment typu ScaledObject. W tym YAML-u możemy określić m.in. reguły dla naszego skalowania oraz wybrać kontenery, które mają zostać powielane.
Oto przykład:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: keda-service-bus-function
labels:
deploymentName: keda-service-bus-function
spec:
scaleTargetRef:
deploymentName: keda-service-bus-function
containerName: azure-functions-container
pollingInterval: 30
cooldownPeriod: 300
minReplicaCount: 1
maxReplicaCount: 500
triggers:
type: azure-servicebus
metadata:
queueName: my-queue
connection: SB_CONN_STRING
queueLength: '10'
Znajomość konfiguracji, jaką dostarcza ten obiekt, jest niezbędna, aby stworzyć środowiska efektywnie skalujące. Zwróćmy chociażby uwagę na minReplicaCount, który ustawiony na 1 będzie chronił nas przed wystąpieniem tzw. cold startu.
Szczegółowe informacje na temat konstrukcji obiektu ScaledObject znajdziecie na GitHubie.
KEDA – integracja z Azure Functions
Myśląc o projekcie KEDA, na pewno zastanawiacie się, w jaki sposób można go wykorzystać w swojej architekturze. Jeżeli chodzi o Microsoft Azure, pierwszym zastosowaniem będzie migracja Azure Functions do Kubernetesa.
Taka możliwość istniała już wcześniej – od jakiegoś czasu można uruchomić Azure Functions w kontenerze Dockera, a dalej w K8S. Tutaj KEDA niczym się nie wyróżnia.
Natomiast dotychczas sami musieliśmy zadbać o stworzenie odpowiedniego orkiestratora, który skalował instancje naszej funkcji. Teraz wszystkim tym KEDA zajmie się za nas, jako nasz Scale Controller.
KEDA a Azure Functions Core Tools
Wraz z pojawieniem się projektu KEDA, Microsoft zmodyfikował Azure Functions Core Tools. Integracja z Azure Functions dotyczy tutaj właśnie tych narzędzi, które zyskały nową komendę wiersza poleceń:
func kubernetes
Zobaczmy, jak można z niej skorzystać.
KEDA w praktyce
W tym krótkim demo stworzymy Azure Function, która powinna zostać wyskalowana przez KED-ę w naszym klastrze.
1. Zacznijmy od listy niezbędnych narzędzi i komponentów:
- Azure Functions Core Tools (wersja minimum 2.7) – dostępne tutaj
- Visual Studio Code (z dodatkiem Azure Functions)
- Kubectl połączone z naszym klastrem
- Docker
Ja swój klaster skonfigurowałem w Azure (AKS), a dodatkowo utworzyłem następujące usługi:
- Azure Service Bus (wraz z Queue).
- Azure Storage Account (dla naszych funkcji)
- Azure Container Registry (tutaj trafi nasza funkcja – obraz Dockera, przed uruchomieniem w K8S)
2. Następnie przenosimy się do Visual Studio Code i tworzymy nową funkcję, wykorzystując wcześniej wspomniane rozszerzenie: https://code.visualstudio.com/tutorials/functions-extension/create-function

Zauważcie, że w linii 19 usypiam wątek na 30 sekund. Robię to wyłącznie w celu łatwiejszego pokazania, że skalowanie faktycznie działa.
3. Idziemy dalej. W local.settings.json powinniśmy dostarczyć konfigurację dla dwóch ustawień:
- AzureWebJobStorage – tutaj podajemy wartość Connection String do wcześniej utworzonego Azure Storage.
- keda-test_SERVICEBUS – to Connection String dla naszego Service Bus.
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "DefaultEndpointsProtocol=……",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"keda-test_SERVICEBUS": "Endpoint=sb://…..
}
}
Instalacja KED-y w klastrze
4. Zajmijmy się teraz instalacją KEDA w naszym klastrze. Tu właśnie z pomocą przychodzi nam wspomniana wcześniej integracja. Jedyne, co musimy zrobić z poziomu terminala, to wywołać polecenie:
func kubernetes install --namespace keda-test
W GitHubie, na stronie projektu KEDA, znajdziecie inne możliwości instalacji, jak np. Helm. Tutaj skupiamy się jednak na rozwiązaniach Azure Function Core Tools.
Zerknijmy, co nowego pojawiło się w naszym środowisku:
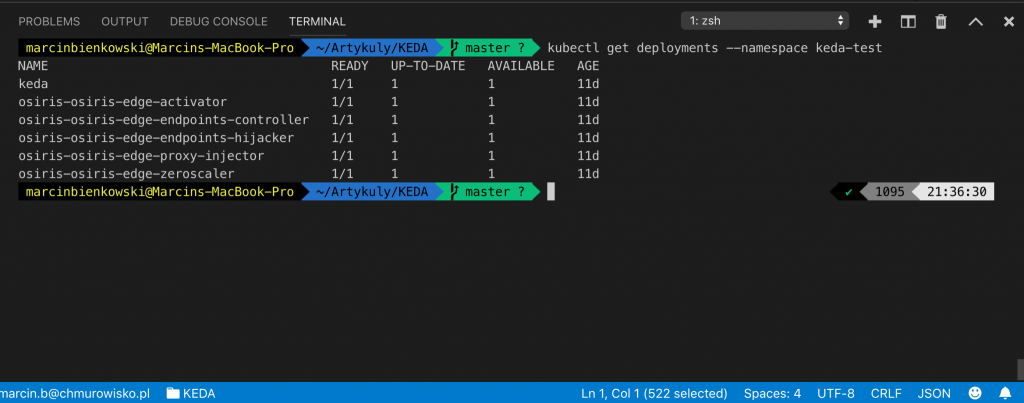
I tutaj mamy pewną nowość, o której nie pisałem wcześniej. Oprócz KED-y zainstalowaliśmy także komponent Osiris.
Jest to niezależny komponent odpowiadający za skalowanie funkcji, których inputem jest żądanie HTTP. Sama KEDA odpowiada natomiast za pozostałe funkcje (nie HTTP).
5. Kolejny krok to przygotowanie naszej funkcji do działania w kontenerze. I tutaj znowu wszystko jest banalnie proste, robimy to właściwie jednym poleceniem:
func init –docker
Nietrudno się domyślić, że efektem będzie pojawienie się nowego pliku Dockerfile w projekcie.
6. W tym momencie polecam Wam skompilować cały projekt i przyjrzeć się oknu ostrzeżeń i błędów w Visual Studio Code. Jeżeli wszystko jest ok, możemy przystąpić do ostatniego etapu – uruchomienia naszej funkcji.
7. Sam deployment przeprowadzamy za pomocą poniższego polecenia:
func kubernetes deploy \
--name keda-service-bus-function \
--namespace keda-test \
--registry kedatest.azurecr.io/keda-service-bus-function
--pull-secret regcred
Omówmy teraz jego parametry:
- name – nazwa naszej funkcji
- namespace – przestrzeń nazw, w której znajdzie się nasza funkcja
- registry – adres/nazwa obrazu, do którego zostanie „wypchnięta” funkcja; ja korzystam z Azure Container Registry
- pull-secret – zdefiniowany wcześniej przeze mnie „secret”, który pozwala naszemu klastrowi pobrać obraz z repozytorium. Jak go zdefiniować, możecie sprawdzić tutaj.
Pamiętajcie też, że przed wywołaniem tego polecenia musicie być również zalogowani w terminalu do Waszego zdalnego repozytorium Dockera.
Konfiguracja KED-y w klastrze
Sprawdźmy teraz, czy udało nam się prawidłowo skonfigurować KED-ę w naszym klastrze.
Moja funkcja posiada Trigger Queue – Service Bus. Muszę więc użyć mechanizmu, który wygeneruje wiadomości w mojej kolejce. Tutaj mogę wskazać trzy rozwiązania (ja wybrałem ostatnią opcję):
- Stworzenie Azure Functions w portalu.
- Napisanie prostego generatora wiadomości dla kolejki Service Bus w projekcie .NET w Visual Studio Code lub Visual Studio.
- Użycie Service Bus Explorer (https://github.com/paolosalvatori/ServiceBusExplorer).
W moim przypadku chodziło o jak najszybsze przetestowanie rozwiązania, skorzystałem zatem z gotowej aplikacji, która nie wymaga niczego więcej poza instalacją i połączeniem z Service Bus.
W czasie dodawania wiadomości do kolejki kilkukrotnie celowo wywołałem następujące polecenie:
kubectl get pods --namespace keda-test | grep 'keda-service-bus-function'
Jak możecie zauważyć na grafice poniżej, nasze rozwiązanie zadziałało. Funkcja najpierw została przeskalowana przez KED-ę (od 0 do 1), a następnie HPA zadbał o dalsze skalowanie naszych POD-ów.

KEDA – podsumowanie
Projekt KEDA jest obecnie we wstępnej fazie rozwoju i nie zaleca się wdrażania go „na produkcji”. Mimo to, warto go obserwować i poznać jego mechanizmy, szczególnie że architektura oparta o zdarzenia jest dosyć popularna na platformie Azure.
Warto również pamiętać o funkcjonalności Virtual Nodes, jeżeli korzystamy z usługi AKS. Możemy wtedy pomyśleć o skalowaniu naszych funkcji do Azure Container Instances, co stanowi na pewno bardzo ciekawe rozszerzenie możliwości całego środowiska.
Z pewnością KEDA ma ograniczone zastosowanie z powodu niewielkiej liczby scalerów. Natomiast obecnie trwają prace nad dodaniem obsługi m.in. CosmosDB czy Azure Iot Hub, co znacznie zwiększy użyteczność projektu.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.