Amazon Mnie (Nie) Znienawidzi… Czyli Jak Płacić Mniej za Chmurę AWS i Zostać Bohaterem w Twojej Firmie


Innowacja innowacją, ale elementu kosztowego nie da się przeskoczyć w 99% firm. Dziś pokażę Ci 36 sposobów jak płacić mniej zac chmurę AWS i zostać bohaterem w swojej firmie.
Czytaj dalej…
Jeżeli zaczniesz używać Amazon Web Service bez poniższych kroków, po roku czasu będziesz płacił tyle samo lub więcej, co za standardową infrastrukturę lub usługi innego dostawcy chmury.
Nikt nie będzie zadowolony.
Ani Ty, bo wybrałeś rozwiązanie i teraz świecisz oczami przed szefem. Ani Twój szef, bo nie widzi przełożenia na liczby. Ani Amazon Web Services, bo Twój biznes nie będzie się rozwijał na ich infrastrukturze.
Zdradzę Ci sekret.
Amazon i część innych firm dostarczających usługi w modelu as-a-services, chce, abyś wykorzystywał optymalizację kosztową, płacił jak najmniej, wykorzystywał więcej i więcej. Jeżeli tego nie zrobią, to po pewnym czasie, jest szansa, że zrezygnujesz z ich usług.
Nikt tu nie wygrywa.
OK. Wdrożyłeś wszystkie metody optymalizacji i co dalej? Dziś płacisz rachunek na $1,000, a za rok płacisz $10,000. To dobrze? to źle? Miało być taniej… Ceny wzrosły? A może Twój biznes wzrósł 20x? Who knows? CFO pewnie powie, że lecisz w kulki. Miało być $1000.
Zdradzę Ci kolejny sekret.
Optymalizacje po stronie Amazon Web Services to tylko 20% sukcesu. Kolejne 80% leży u Ciebie i w Twojej organizacji. Powinieneś wiedzieć, jak przełożyć nowy model rozliczania na Twoją organizację. Powinieneś umieć pokazać.
Jakie jest rozwiązanie? Spójrzmy na listę. Lista ta zawiera wiele pomysłów, które są wynikiem pracy z polskimi klientami, czytaniem blogów (szczególnie Cloudability i Cloudyn) oraz oglądania sesji na kanale AWS.
Zmniejszanie Kosztów Instancji
Wykorzystuj Instancje Reserved
Naliczanie hajsu w AWS jest godzionowe. Każda rozpoczęta godzina pracy instancji to x pieniędzy.
Instancje Reserved w Amazon Web Services to swego rodzaju kontrakt. Decydujesz się na 1 rok lub na 3 lata płacenia za pewną instancję, w zamian za zniżki. O jakich zniżkach mówimy?
- Przy kontrakcie na 1 rok – 20-40%
- Przy kontakcie na 3 lata – 50-60%
Ceny te oczywiście zależą od rodzaju instancji, regionu i wielu innych czynników, jednak te ceny możesz zobaczyć np. tu.
Masz też trzy opcje płacenia:
- All Upfront – najtańsza opcja
- Partial Upfront – część z góry, część co miesiąc
- No Upfront – płacisz co miesiąc pomniejszoną stawkę
Jednym z problemów jest zrozumienie czym tak na prawdę jest instancja Reserved.
Instancja Reserved jest niczym innym jak wirtualnym kuponem, który przypina się do pierwszej wolnej instancji odpowiadającej zakupowi. Jeżeli kupiłeś instancję Reserved na maszynę m3.2xlarge w zonie eu-west-1a i taka instancja powstanie w tej zonie, to od razu nastąpi naliczanie po stawkach Reserved. Kupon jest współdzielony na wiele podłączonych kont – consolidated billing. Gdy tylko pojawia się instancja pasująca zakupowi, od razu następuje naliczanie po nowych cenach.
Klienci boją się, że zostaną przywiązani do infrastruktury. Boją się, że zmienią im się wymagania. Moje obserwacje pokazują jednak, że jest to najlepsza forma oszczędzania. Amazon umożliwia modyfikację instancji Reserved (na mniejsze, większe). Warto więc podejmować decyzje szybko monitorując użycie maszyn i środowiska.
Polecam też dobre nagranie poświęcone instancjom Reserved.
Poniżej obraz pokazujący wykorzystanie i oszczędności instancji Reserved w modelu No Upfront dla instancji t2.micro.

Kupuj Instancje Reserved Wcześnie i Często
Zespół Cloudability dokonał pomiarów i doszli do wniosku, że należy kupować instancje szybko i często.
Jeżeli podejmujesz decyzje o zakupie:
- rocznie – oszczędzasz do 34%
- kwartalnie – oszczędzasz do 63%
- miesięcznie – oszczędzasz do 69%
Ale skąd te liczby?
Budując swoje środowisko kupujesz nowe maszyny, budujesz grupy Auto Scaling, usuwasz maszyny, robisz różne dziwactwa dla dobra swoich użytkowników.
Robisz to na instancjach On Demand (rozliczanych co godzinę). Jeżeli dokonujesz decyzji o zakupie instancji Reserved w grudniu, a postawiłeś nowe środowisko w styczniu, to co się dzieje? 11-12 miesięcy płacisz stawki On Demand za część środowiska.
Warto to robić często i podejmować dobre decyzje. W późniejszych punktach wyjaśnię, co może Ci dodatkowo pomóc, aby podejmować lepsze decyzje.
Zamieniaj Instancje Reserved
Jeżeli masz konto bankowe w USA możesz odsprzedawać nieużywane instancje Reserved. W Polsce jest to niemożliwe.
Możesz natomiast zmieniać instancje na większe lub mniejsze w ramach jednej rodziny. Pojawia się pojęcie Normalization Factor. Możesz więc zamienić 4 instancje m3.large na 8 instancji m3.medium. Zmiana w drugą stronę też działa.
Należy jednak pamiętać, że zmiana może się odbyć w ramach jednej rodziny, w tym samym regionie oraz z tym samym systemem operacyjnym (Windows na Linux nie jest możliwe).
Kupuj Instancje Spot
Jedną z najbardziej tajemniczych, ale też najbardziej dochodowych operacji jest użycie instancji Spot. Są to instancje, które licytujemy. Mówimy, że zapłacimy za nią X. Jeżeli Amazon uzna, że jest w stanie nam dostarczyć maszynę w tej cenie, to dostaniemy ją.
Pozwala ona zaoszczędzić nawet 90% ceny instancji On Demand.
Say what? 90% ??????????
No tak.
Jest to taka sama instancja jak On Demand, z jedną małą różnicą. AWS jest w stanie wyłączyć Ci ją gdy tylko znajdzie się ktoś, kto zapłaci za nią więcej niż Ty. Jeżeli znajdzie się ktoś kto zapłaci większą cenę, to po 2 minutach stracisz swoją instancje i wszystkie dane, które na niej posiadałeś.
Say what? Stracę dane ?????? Po co to komu?
Wyobraź sobie, że masz serwery, które pobierają z zewnętrznego zasobu dyskowego filmy video w formacie mp4, konwertują na avi i wrzucają spowrotem na dysk. Robią tak w kółko. Czy stanie się coś złego, jak któryś z takich serwerów zostanie usunięty. Raczej nie. Zostanie powołana nowa maszyna, która obrobi film jeszcze raz.
Są miejsca, do których instancje Spot nie znajdą zastosowania (serwery bazodanowe). Są takie do których mogą być użyte (serwery aplikacyjne). Są takie, do których są wskazane (serwery wykonujące asymetryczne zadania).
Nie wiem czy wiesz, ale na rynku polskim działa startup bidelastic, w którym pracują eksperci zajmujący się rynkiem Spot. Warto obejrzeć nagranie Przemka, który opowiada więcej o instancjach Spot w Amazon Web Services:
Wyłączaj Nieużywane Instancje
Największą zaletą chmury jest to, że każdą z instancji możesz usunąć w dowolnym momencie i przestaniesz za nią płacić. Nawet posiadając instancje Reserved, możesz usunąć daną instancję, a koszty Reserved przeniosą się w inne miejsce.
Przy dużym środowisku pojawiają się nowe problemy. Uruchomione są maszyny, które nie są potrzebne.
Warto więc wprowadzić cykliczne czyszczenie środowiska. Warto spisać to w zasadach korzystania ze środowiska, a nawet oskryptować.
Dam Ci przykład.
Jeżeli dana maszyna posiada obciążenie procesora na poniżej 1%, brak operacji I/O przez większość dnia oraz brak ruchu wyjściowego, to należy ją usunąć.
Nie brutalnie, ale usunąć. Spotkać się z właścicielem instancji i porozmawiać o optymalizacji. Później zdradzę Ci kilka sposobów, jak można „zmusić” kogoś do optymalizacji.
W chmurze można dojść do średniego wykorzystania maszyn na poziomie 50%. Może więc dany workload można przenieść na inną maszynę, może użyć mniejszej maszyny, może powoływać instancję tylko na określoną część dnia, a może przenieść wykonanie pewnej funkcji do AWS Lambda.
Naucz Się Wykorzystywać Bursting dla EC2
W AWS występuje wiele rodzin instancji. Są instancje compute optimized, memory optimized, storage optimized, GPU instances oraz general purpose.
W skład tej ostatniej grupy wchodzą instancje t2, a dokładniej instancje t2.micro, t2.small, t2.medium, t2.large.
Są to niezwykle tanie instancje, ale mają pewien haczyk. Otóż każda z tych instancji posiada base performance, czyli % wykorzystania procesora. Ten cały base performance może być zwiększany do 100%.
Pozwól, że posłużę się przykładem instancji t2.medium.
- Initial CPU Credit: 60
- CPU Credit earned per hour: 24
- Base performance: 40%
- Maximum earned CPU credit balance: 576
Instancja t2.medium posiada dwa rdzenie. Na starcie instancja t2.medium posiada 60 kredytów. Pozwala to na wykorzystanie rdzenia w 100% przez 60 minut lub dwóch rdzeni w 100% przez 30 minut.
Jeżeli kredyty się skończą, to wydajność procesorów spada do 40% dla jednego rdzenia, albo 2 x 20% przy wykorzystaniu dwóch rdzeni.
W ciągu godziny, gdy maszyna się nudzi (czyli wykorzystanie procesorów jest poniżej base performance), to dodawane są kredyty. W przypadku t2.medium są to 24 kredyty na godzinę. Maksymalnie do 576 kredytów (+ startowe kredyty).
Tym samym możesz wykorzystywać maszynę w 100% możliwości przez ponad 10 godzin.
Wyobraź teraz sobie, że posiadasz aplikację, która jest mocno wykorzystywana z rana i wieczorem, a przez resztę doby się nudzi. Widzisz idee?
Jeżeli uznasz, że zmiana z m3.medium na t2.medium jest dobra, to otrzymasz oszczędność na poziomie 11%. Jeżeli zmiana z c3.large na t2.medium spełni Twoje oczekiwania to masz 46% oszczędności.
Dodaj do tego instancje Reserved i Auto Scaling i nagle dochodzimy do gigantycznych oszczędności.
Zaczynasz zauważać zaletę chmury i optymalizacji kosztowej? Zaczynasz zauważać, dlaczego standardowe porównanie kosztów, bez przemyślenia i testów wypada słabo? Zaczynasz zauważać, dlaczego firmy, które używają AWS od lat, mają ROI na poziomie 560%?
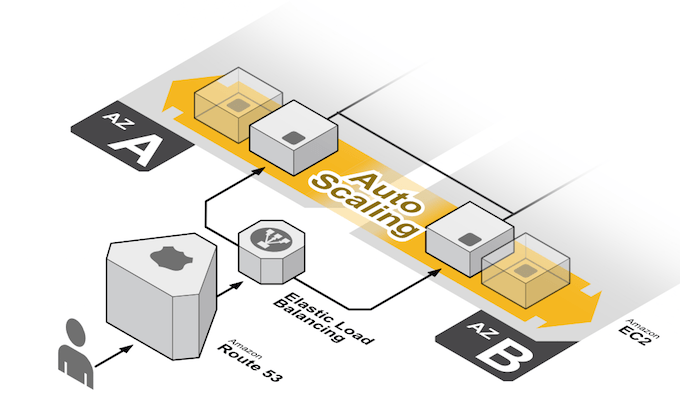
Autoskaluj. Projektuj Dla Elastyczności, A Nie Dla Maksymalnej Wydajności.
Auto Scaling jest jedną z największych zalet chmury i możliwością na zapewnienie sobie spokojnego życia oraz dużych oszczędności.
O co z tym chodzi?
Amazon Web Services pozwala Ci zbudować rozwiązanie, które rośnie i maleje, kiedy nastąpi przekroczenie pewnego elementu.
W momencie, gdy np. średnie wykorzystanie procesora w klastrze wzrośnie do 40%, następuje dodanie nowych instancji z przygotowanego obrazu.
Tym samym możemy zbudować rozwiązanie, które w stanie spoczynku składa się z 2 instancji t2.medium. Jeżeli w ciągu dnia otrzymamy dużo ruchu, to możemy dodać np. do 20 nowych instancji. Jeżeli ruch spadnie, to stopniowo wrócimy do 2 instancji.
Skalowanie wymaga od nas przeprojektowania aplikacji, aby dodanie lub odjęcie serwera nie spowodowało utraty pewnych informacji. Robi się to przez wyniesienie stanu sesji do DynamoDB lub memcached oraz wyniesienie plików statycznych do S3 lub CloudFront.
Skalowanie działa w górę, jak i w dół. Co jest ważne z punktu widzenie kosztów. Nawet w Polsce spotkałem się z firmami, które zakładały 8 serwerów na frontend aplikacji. Po dodaniu takiego środowiska do grupy Auto Scaling, środowisko kurczyło się do 4 serwerów. Koszty 🙂
Skalować możemy też wg. harmonogramu. Zakładamy duży ruch o godzinie 20:00. Dodajmy to do polityki i maszyny zaczną się dodawać w oczekiwaniu na duży ruch.
Złota zasada: Skaluj w górę tak szybko jak się da, aby obsłużyć cały ruch. Skaluj w dół tak wolno jak się da, gdyż naliczanie jest godzinowe.
Spędzaj Dużo Czasu Optymalizując Instancje
Zmiana instancji m4.2xlarge na c4.2xlarge to oszczędność 9%. Zmiana instancji m4.2xlarge na r3.xlarge to oszczędność 35%. Wspomniana już zmiana c3.large na t2.medium to oszczędność 46%.
Widzisz więc jak ważne jest optymalizowanie środowiska i ciągłe sprawdzanie co jest dobre dla Twojej aplikacji. W prosty sposób testy swojej aplikacji na instancjach Spot lub On Demand. Na bazie testów podjąć decyzje i ruszyć z optymalizacją.
Warto też zmieniać stare typy instancji na nowe wewnątrz rodziny.
Warto zmienić T1 na T2, M1 na M4, C1 na C4. Za podobną cenę otrzymamy mocniejsze maszyny, co może wpłynąć na ich ilość w produkcyjnym środowisku.
AWS posiada serwis EBS (Elastic Block Storage), który bardzo ułatwia zmianę maszyn. Dysk z systemem i plikami zostaje podłączony do nowej maszyny.
Warto wydać dużo więcej na narzędzia, które ułatwią Ci podejmowanie decyzji, np. Cloudability, Cloudyn, czy też Netflix ICE.
Pamiętaj! Nie ma wyznacznika. Nie ma magicznego narzędzia
Czy lepiej użyć 8 instancji medium, czy może 2 instancje xlarge?
Używaj narzędzi, testuj, testuj, testuj i podejmuj dobre decyzje.

Zmniejszanie Kosztów Innych Usług AWS
Wykorzystuj Free Tier
Od chwili założenia konta, przez cały rok, masz możliwość używania opcji Free Tier. Ta opcja nie jest szczególnie dobra dla instancji EC2 (jedna instancja t2.micro z Linux i jedna instancja t2.micro z Windows), ale jest bardzo przyjemna dla innych serwisów.
Dla przykładu:
- AWS Device Farm – 250 urządzenio-minut za darmo
- Amazon API Gateway – 1 milion API calls
- DynamoDB – 25 GB, 25 Units Read Capacity i 25 Units Write Capacity
Na tej stronie znajdziesz wszystkie potrzebne informacje.
Wykorzystuj Bursting EBS
Sekundkę Mirek.
Przecież już było o burstingu…
Było o burstingu CPU w instancjach t2, teraz czas na EBS.
EBS to po blokowy zasób dyskowy, który używany jest przez instancje. Nie będę się teraz rozpisywał o lokalnym storage. Skupmy się na EBS. Trwały, nieulotny storage, dla którego określasz pojemność (GB) i wydajność (IOPS).
Do dyspozycji masz trzy opcje:
- Magnetic – dyski magnetyczne – zapomnij
- Dyski SSD – na każdy 1 GB przypadają 3 IOPSy
- Dyski SSD z rezerwą IOPS – określasz ile IOPS potrzebujesz
Dyski z rezerwą są fajne. Potrzebujesz 20GB i 1000 IOPS. Boom i masz. Dla niektórych aplikacji fajne, ale co jeżeli potrzebuję więcej IOPS tylko czasami?
Zwykłe dyski SSD mają dodatkową moc. Bursting. Wszystkie dyski SSD poniżej 1 TB mają opcję burstingu do 3000 IOPS.
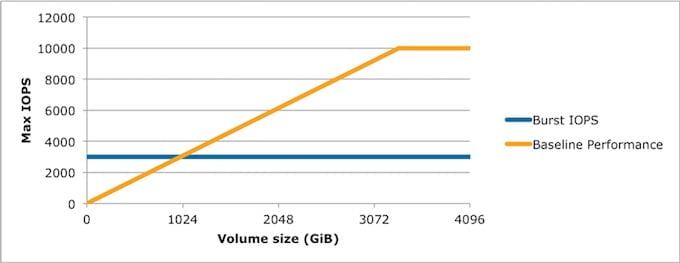
Posłużmy się przykładem.
Posiadasz dysk SSD o pojemności 100 GB. Standardowo możesz wyciągnąć z niego 300 IOPS. 3 IOPS per 1 GB. Każdy dysk SSD otrzymuje przy tworzeniu 5,400,000 kredytów I/O. Pozwala to na uzyskanie 3000 IOPS przez 30 minut. 1 kredyt to 1 operacja I/O na sekundę.
Napełnienie stanu kredytów do pełna zajmuje dla dysku 100 GB trwa 5 godzin. Jeżeli więc nie wykorzystujesz IOPS w danej chwili trafia to do puli kredytów. Im większy dysk, to szybciej ta pula się napełnia i dłużej możesz wykorzystywać granicę 3000 IOPS.
Do części aplikacji, które potrzebują dużo IOPS tylko czasami, możesz użyć standardowych dysków SSD. Tym samym koszta spadną, a Ty możesz przejść do kolejnego punktu.
Opcja Reserved Nie Tylko Dla EC2
O opcji Reserved pisaliśmy już dużo. Należy jednak wspomnieć o jeszcze jednej rzeczy.
Opcje Reserved można też stosować dla DynamoDB, RDS, Redshift, ElastiCache i Cloudfront.
DynamoDB, czyli baza NoSQL od Amazon, pozwala zarezerwować Write Capacity Units i Read Capacity Units na okres 1-3 lat.
CloudFront (system CDN) pozwala zarezerwować pewną ilość ruchu na okres powyżej 12 miesięcy.
RDS (serwis zarządzania bazami SQL), Redshift (hurtownia danych) oraz ElastiCache (serwis cache Redis i memcached), pozwalają zarezerwować instancje na okres 1-3 lat.
Każda z tych opcji (szczególnie CloudFront) pozwalają mocno obniżyć koszty, przy rezerwacji zasobów.
Usuwaj Mało Używane Zasoby
Do swojego Data Center kupowałeś X serwerów, pulę adresów IP, dyski i inne zasoby. Jeżeli ich nie używałeś nie działo się nic złego. Przecież już za to zapłaciliśmy. Niech leży.
W chmurze masz szansę na obniżanie kosztów na każdym kroku. Jeżeli już czytałeś mój poradnik Za Co Płacimy w AWS, to pewnie wiesz, że jest BARDZO duża składników kosztowych każdej z usług.
Posiadasz nieużywane dyski EBS, nie potrzebujesz snapshotu, nie potrzebujesz obrazu AMI, nie potrzebujesz danego adresu IP, Twoja baza danych nie ma aktywnych połączeń? USUWAJ.
Ustal okresowe czyszczenie zasobów i usuwaj niepotrzebne rzeczy. Koszta spadają i zmniejsza się bałagan.
Do sprawdzenia co usunąć możesz użyć CloudCheckr lub narzędzia AWS Trusted Advisor.
Amazon poświęcił setki godzin pracy swoich programistów, aby stworzyć narzędzie, które pokaże Ci, w jaki sposób możesz płacić mniej dla Amazon. Dziwne? Mądre.
Zostań Królem Kosztów w S3
Simple Storage Service to jedna z najpopularniejszych usług AWS. Pozwala Ci składować pliki. Dużo plików.
S3 pozwala Ci wrzucić nieskończoną ilość plików o rozmiarze do 5TB, zapewniając przy tym żywotność pliku na poziomie 99,999999999%. Amazon robi dużo kopii Twojego pliku w obrębie jednego regionu (między dziesiątkami Data Center). Twoje dane zawsze zostają w regionie, do którego je wrzuciłeś.
Przy kilku GB koszta nie są tak ważne. $0.03 za 1 GB. Jeżeli jednak uzbierasz kilka-kilkadziesiąt Peta Bajtów. Koszta zaczynają mieć znaczenie.
Masz kilka opcji optymalizacji.
Jedną z nich jest wykorzystanie Reduced Redundancy S3, posiadającego żywotność na poziomie 99,99%. Jeżeli Twoje dane nie są aż tak bardzo ważne i strata jednego pliku od czasu do czasu, nie jest problemem, możesz skorzystać z tej opcji i zaoszczędzić około 20% kosztów.
Inną opcją jest wykorzystanie Amazon Glacier. Usługi archiwizacji. Dalej posiadamy żywotność na poziomie 99,999999999%, ale oszczędzamy do 64% kosztów.
Jak to możliwe?
Dane w Glacier składowane są na określonej kopii płyt Blue-Ray (tak przynajmniej wynika z opisów blogerów). Dane są bezpieczne, leżą sobie spokojnie. Ale jeżeli chcesz je odzyskać musisz poczekać 3-5 godzin na rozpoczęcie odzyskiwania.
Jeżeli dane mają być wyjmowane często, to Glacier nie jest dobry. Jeżeli natomiast chcesz używać S3 do archiwizacji i nie ruszać tych danych przez lata, to Glacier jest dla Ciebie.
Dodatkowo Amazon S3 umożliwia Ci budowanie polityk Lifecycle. W prosty sposób możesz określić, aby dany plik po 30 dniach w S3 powędrował do Glacier i po kolejnych 30 dniach został usunięty z S3.
Cache When You Can
Rozmawiając z przeróżnymi architektami, obserwując jak działają wielkie firmy tego świata i pracując przy kilku ciekawych projektach, nauczyłem się: Cache When You Can.
Ale jaki to ma związek z kosztami?
Ależ ogromny. Jeżeli przy każdym zapytaniu klienta, serwer aplikacyjny musi odpytać bazę danych, policzyć wyniki, a serwer frontend wygenerować stronę, to potrzeba na to gigantycznie dużo zasobów.
Różne rozwiązania można stosować w różnych częściach środowiska. Cache w przeglądarce, cache na poziomie CDN, proxy, cache na poziomie serwera aplikacji, Key-Value store i tak dalej.
AWS dostarcza również narzędzi do części z powyższych. Do dyspozycji mamy ElastiCache, czyli serwis udostępniający zarządzany przez AWS Redis lub memcached. Mamy też CloudFront, czyli globalny CDN, buforujący treść statyczną oraz dynamiczna.
Przy dobrej architekturze nagle schodzimy z 4 instancji z 64 GB RAM na 2 instancje z 16 GB RAM.

Inne Możliwości z Poziomu AWS
Wykorzystuj Zniżki Dla Instancji EC2
Rośniesz? To dobrze. Do dyspozycji masz zniżki dla instancji EC2.
Dostępne są niestety przy dużych wydatkach, ale są. Jeżeli posiadasz dużą ilość instancji reserved, możesz liczyć na dodatkowe zniżki na poziomie 5-10%.
Dużo zaczyna się na poziomie $500000.
Wydaje się to dużo, ale pamiętaj, że instancje Reserved mogą pracować przy opcji consolidated billing. Jeżeli Twoja firma jest globalna lub posiadasz dużo klientów, warto łączyć instancje w jedno konto. Możesz dojść do dużych poziomów kosztów i tym samym zacząć negocjować koszta z Amazon.
Wykorzystuj Bardziej Realne Zniżki
Jeżeli startujesz z jednym serwerem lub serwisem musisz się dostosować do standardowych cen.
Ale rośniesz. Zaczynasz używać więcej pasma, przechowujesz więcej plików na S3. Dochodzą nowe serwisy. Dołączasz nowe oddziały do swojego konta (w ramach consolidated billing). Dochodzisz do większych kosztów.
Pojawia się opcja zniżek.Część serwisów oferuje takie zniżki w bardzo rozsądnych wymiarach.
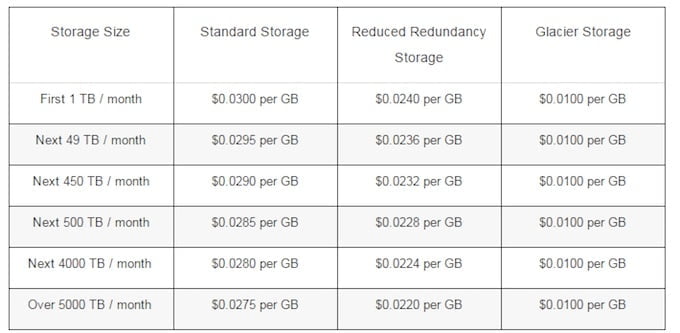
Spójrzmy np. na Amazon S3. Pierwszy 1TB kosztuje $0.03/GB. Wszystko powyżej 5PB kosztuje $0.0275/GB.
Spójrzmy np. na transfer danych. Pierwsze 10TB kosztuje $0.09/GB. Wszystko powyżej 350TB kosztuje $0.05/GB.
Im bardziej rośniesz i konsolidujesz zasoby, tym płacisz mniej. Nic nie robisz. Po przekroczeniu każdego z progów, dla każdego z serwisów, Amazon policzy Ci koszta po nowych cenach.
Kontroluj Kto Uruchamia Zasoby
Startując z AWS, bardzo łatwo jest popełnić błąd i używać jednego konta. Zdarza się też, że pół firmy używa konta z polityką AdministratorAccess.
Po pierwsze taka osoba może usunąć każdy zasób i każdy plik. Po drugie taka osoba może stworzyć każdy zasób i każdy plik, o ile ograniczenie Amazon go nie zablokuje.
To duże wyzwanie kosztowe, ale też olbrzymia dziura w bezpieczeństwie.

Nie odkładaj tego. Już pierwszego dnia zaprzyjaźnij się z serwisem IAM. Pozwoli Ci to ustalić zasady, co i gdzie dana osoba może. Szczególnie co i gdzie może tworzyć oraz co i gdzie może usuwać.
Wykorzystuj Linked Accounts
AWS pozwala Ci tworzyć dodatkowe konta i agregować je w jedno główne, z którego będziesz się rozliczał.
Jaki to ma sens? Głównie organizacyjny. Tworząc dla różnych osób, dla różnych zespołów lub dla różnych projektów, otrzymujesz przejrzystość tego co się dzieje.
Polityka IAM staje się prosta. Masz mniej zasobów, które musisz kontrolować. Łatwiej Ci określać kto za co płaci.
Wymagaj Tagów
Tagi w AWS to kolejna opcja po Linked Accounts na określanie co jest czym i do kogo należy. Tagi są MASSIVE.
Używaj tagów i wymagaj tagów.
Tagi to po prostu pewien ciąg znaków określający dany element w AWS.
Polecam swoim klientom, aby używali następujących tagów: Name, Project, Create, Delete, Owner.
Np.
- Name: IR-UB-FR-001
- Project: ITCM
- Create: 2015.07.01
- Delete: 2016.02.01
- Owner: MB
Co wiem z takiego opisu? Jest to serwer 001 w Irlandii, Ubuntu, pracuje jako Fronend w projekcie ITCM. Stworzył go MB 2015.07.01. Po 2016.02.01 nie powinien już istnieć.
I teraz najciekawsze. Każdego z tych tagów możesz używać do przydzielania kosztów i podejmowania decyzji, czy dane zasoby są potrzebne, czy już nie.
Możesz stosować różne nazwy, ale zasada Keep it Super Simple jest najlepsza. Ustal max. 4-6 tagów i ustal, że każdy w organizacji ma ich używać.
Nie taguj po fakcie. Taguj przy tworzeniu zasobów.
Taguj Wszystko
Tagi to nie tylko instancje. Taguj wszystko. Tagi możesz przydzielić do S3, Route 53, RDS, VPC i wielu innych serwisów.
Dzięki stosowaniu odpowiednich tagów możesz dowiedzieć się jaki bucket S3 jest wykorzystywany przez projekt ITCM. Sprawdzisz ile kosztowało pasmo użyte przez EC2 i S3 dla tego projektu. Sprawdzisz ile snapshotów i replik RDS wykorzystuje ten projekt.
Jednym słowem masz pełny ogląd na wykorzystywane zasoby per Project, Owner, You-Name-IT. Widzisz też koszta każdego z elementów. Możesz wyszukiwać po tagach lub korzystać z narzędzi ala AWS Config. Nieźle co?
Wdróż Politykę Tag Or Die
Wprowadź kulturę tagowania.

Cała ta operacja ma sens, jeżeli wszyscy będą używać tagów. Tym samym możliwe będzie przydzielanie kosztów i inne opcje (o których za chwile)
Nic tak nie działa jak opcja Tag or Die. No Tags, No Instances.
Regularnie sprawdzaj w konsoli lub za pomocą skryptów, czy wszystkie zasoby mają tagi, jeżeli nie mają, po prostu je usuń. Posłuchaj kto płacze i go zwolnij… no może nie zwalniaj, ale daj mu do zrozumienia, że instancja lub inny zasób bez tagów nie będzie istniał w Twoim środowisku.
Wyłapuj Błędy Programowo
Sprawdzanie ręczne i skryptami jest dobre na początku. Później musisz zautomatyzować proces tworzenia maszyn oraz sprawdzania polityk.
W dobrze zrobionym środowisku, developer nie musi podawać tagów. Tagi tworzone są automatycznie, gdy tworzone jest środowisko w CloudFormation, Packer, Vagrant lub innych narzędziach.
Maszyny, które przekroczyły termin ważności powinny być usuwane. Środowiska powiązane z projektem, który został zabity powinny być usuwane.
Nie zgaduj. Spisz procesy i implementuj je w środowisku AWS. Dodatkowo wyłapuj błędy w tagach. Różne nazwy takie jak Prod/Produkcja/Proudkcja powinny być traktowane jako jedna nazwa.
Wdróż Budżetowanie
Budżetowanie to nowa opcja dostępna od czerwca 2015. Pozwala na określanie budżetów per Availability Zone, Linked Account, API Operation, Instancje Reserved/Non-Reserved, Serwis oraz TAG.

Dzięki budżetowaniu możesz określić ile przewidujesz pieniędzy per projekt X, który określony jest tagiem Y.
Ustawiaj Progi Powiadomień
W AWS masz możliwość ustawiania alarmów z poziomu CloudWatch. Alarmy można ustawiać dla każdej z metryk, dla każdego z serwisów. Można też ich użyć do śledzenia kosztów w AWS.
Ustaw politykę, która wyśle mail developerowi, kiedy jego budżet osiągnie 60%. Jego dyrektorowi, gdy budżet osiągnie 90% oraz do CFO, gdy budżet przekroczy 100%.
Wykorzystuj Opcję Wróżki
Opcja budżetowania dodała też funkcję Forecast (wróżka). Z poziomu Cost Explorer dostajesz opcję przewidywania wydatków w AWS na 3 miesiące do przodu.
Możesz sprawdzić ile dany TAG zapłaci za najbliższy miesiąc bazując na danych historycznych. Dane możesz też odnieść do budżetu.
Wykorzystuj Tagi i Linked Accounts do Bardziej Zaawansowanych Reguł
Nie stosuj 1000 tagów. Lepiej w AWS mieć max. 4-6. Dokonuj poważniejszych operacji na plikach bilingowych lub w dedykowanych narzędziach Cloudability, Cloudyn.
Mając projekt i ownera, z którymi powiązany jest dany zasób w AWS, możesz w prosty sposób skorelować wyniki bilingowe z centrum kosztowym, przełożonym, grupą produktową, oddziałem, osobą biznesową, etc.
W ten sposób dopasowujesz wyliczenia do wymogów biznesowych, a nie do serwera, środowiska, etc.
Możesz nareszcie powiedzieć, że projekt, który wystartowaliśmy 3 miesiące temu obciążył dział marketingu o $4586,85. W najbliższym miesiącu koszt wyniesie max. $1342,42 z prawdopodobieństwem 95% oraz $1216,42 z prawdopodobieństwem 80%.
Potężne. Czyż nie? Ale to nie wszystko
Zmiany Organizacyjne
Zaakceptuj Zmianę Chmurowej Rewolucji
Chmurowa rewolucja już przyszła. Oprócz wielu zmian wprowadziła również zmianę w sposobie rozliczania. Jeszcze parę chwil temu za koszta w firmie odpowiadał CIO i robił zakupy kilka razy w roku.

Dzisiaj początkujący developer robi kilka zakupów na godzinę, oczekując na swoje środowisko 1 minutę, a nie 1 miesiąc. Zaakceptuj zmianę i wprowadź odpowiednie zmiany. Skupmy się na kosztach. O DevOps porozmawiamy innym razem.
Wyłączaj Dev/Test na Weekendy i Noce
Jeżeli miałeś Data Center i kolokację, to nie miało znaczenia, że maszyna była włączona 24 godziny na dobę. Nikt przecież nie liczy prądu i klimatyzacji. Na pewno jest darmowa?
Chmura to nie Data Center. Nie musi działać 24 godziny na dobę.
65% godzin to weekendy i noce. 108 godzin per tydzień serwer używany przez danego developera nie powinien pracować. Zakładając 12 godzin pracy (co i tak jest za dużo).
Skrypty, proces i zasady. Środowisko developerskie powinno być gaszone, gdy nie jest używane. Środowisko testowe powinno być uruchomione wyłącznie na czas trwania testów.
Używając takich skryptów, jak Valet, możesz w prosty sposób wyłącza i włącza maszyny w oparciu o tagi i terminach.
Chcesz być dobrym szefem? Wprowadź zasadę, że nie ma opcji stworzenia środowiska developerskiego w AWS pomiędzy 17:00 a 8:00.
Twórz Raporty Użycia Co Tydzień Per Grupa Kosztowa
Po określeniu jakie tagi są dla Ciebie ważne, Twój raport będzie się odkładał w S3.
Od Ciebie zależy co będziesz robił z tymi danymi. Dobrym sposobem jest użycie zewnętrznego narzędzia lub napisanie własnego skryptu, który będzie z pliku CSV składał dane per krupa kosztowa.
Taki raport powinien wylądować u każdej osoby w firmie mającej związek z danym projektem lub danym biznesem.
Dodaj Twoim Ludziom Współczynnik Kosztowy do Celów
Twoi programiści i administratorzy znają już koszta i wiedzą ile dany projekt kosztuje.
Czas na zmianę kultury w firmie. Kultura powinna mieć odzwierciedlenie w prostych elementach. Powinna pokazywać co jest ważne i okazywać to w praktyce, np. nagradzać za kroki zgodne z kulturą organizacji.
Jeżeli prowadzisz firmę w kierunku obniżania kosztów, to czemu nie wprowadzić nagród lub czynnika wpływającego do premii, za określone kwestie finansowe.
You build it, you run it – Verner Vogels (CTO w Amazon)
Dodatkowo dbasz o koszta. Warto więc dodać element kosztowy w swojej firmie każdej osobie pracującej z projektem. Może mieć związek z trzymaniem budżetu lub z zmniejszaniem wydatków per projekt.
Wprowadź Zmienną Jednostkową
Zwiększanie rachunku to nie jest zła rzecz. Może oznaczać, że po prostu nasz biznes rośnie.
Często firma rozwija się szybciej lub dochodzą nowe projekty, więc koszt AWS ciągle rośnie. Potrzebne jest wprowadzenie zmiennej jednostkowej, która otworzy oczy na fakty.

Jeżeli miałbyś wynieść jedną rzecz z tego artykułu, to:
WPROWADŹ ZMIENNĄ JEDNOSTKOWĄ.
WPROWADŹ ZMIENNĄ JEDNOSTKOWĄ.
WPROWADŹ ZMIENNĄ JEDNOSTKOWĄ.
Zaufaj mi.
WPROWADŹ ZMIENNĄ JEDNOSTKOWĄ.
Załóżmy, że Twoja firma posiada 50 portali, które sprzedają reklamy. Dla przykładu portal X posiada 1,000,000 wejść miesięcznie i zarabia $50,000 PLN miesięcznie z reklam.
Postanowiłeś zbudować infrastrukturę pod to w AWS. Po zaprojektowaniu, wdrożeniu, optymalizacji płacisz za środowisko $1,000.
To co powinieneś teraz zrobić, to WPROWADŹ ZMIENNĄ JEDNOSTKOWĄ.
ZMIENNA JEDNOSTKOWA = KOSZT AWS / ZMIENNA BIZNESOWA
Zmienna biznesowa w tym przypadku może być wejściem na stronę – 1,000,000. Koszt AWS to $3,000.
ZMIENNA JEDNOSTKOWA = $3,000/1,000,000 = $0,003
OK i co dalej?
Teraz siadasz na spotkaniu z dowolnie ważną figurą w firmie i mówisz, że zbudowana infrastruktura kosztuje Cię $3000, co wynosi stanowi 16,6% dochodu. Koszt per wejście to $0,003.
Pracujesz dalej. Biznes rośnie. Dodajesz kolejne portale. Pojawia się efekt skali, używasz tagów.
Spotykasz się po raz kolejny i zaczynasz od ZMIENNEJ KOSZTOWEJ. Mówisz, że po Twojej optymalizacji i zwiększeniu ilości użytkowników do 3,000,000, koszt per wejście zmniejszył się do $0,0009.
Podwyżka gwarantowana. Biuro gwarantowane. Wczasy na Kajmanach? Pewnie nie. Zauważ, że nawet nie musisz nic mówić o sumarycznym koszcie per projekt/tag.
Po prostu wykonaj prostą procedurę:
- Wybierz zmienną biznesową: zarejestrowany użytkownik, wejście na stronę, API call, you-name-it.
- Taguje dok�ładnie, aby móc wyliczyć sumaryczny koszt per zmienną biznesową.
- Policz ZMIENNĄ JEDNOSTKOWĄ i graficznie przedstawiaj, jak zmienia się, gdy zmienna biznesowa rośnie.
Wprowadź Grę Cost Ninja
Najlepszy zespół, który zmniejszy zmienną jednostkową dostaje dzień wolny.
Najlepszy zespół, który obniży koszt innego zespołu dostaje dzień wolny.
Opcji jest wiele.
Jeżeli obniżanie kosztów jest ważne w Twojej organizacji, prowadź tą GRĘ otwarcie.
Niech każdy w firmie wie kto wygrał, za co i jak to się przekłada na dochód. Nagle szary developer wpływa bezpośrednio na wynik firmy. Nice.
Zezwalaj Aby Inne Zespoły Widziały Koszta Innych
Niech inne zespoły wiedzą jak wygląda zmiana w optymalizacji kosztowej w danym Business Unit. Niech każda grupa dzieli się swoimi uwagami.
Ważne, aby koszta wynieść z zamkniętych pokoi, do otwartego świata i zacząć traktować to jako coś, nad czym każdy pracuje.
Powołaj w Firmie Cost Optimization Group
Cost Optimization Group jest bardzo częścią składowa Cloud Excellence Center. Grupy w organizacji wspierającej działy programistów w najnowszych technologiach i ułatwiającej wdrażanie nowych procesów i narzędzi. Nazw może przyjąć wiele.
Celem zespołu jest szukanie nowych metod optymalizacji kosztowej i propagowanie tego w grupach, czerpanie od grup i przekazywanie dalej.
Miej pewność, że ta grupa będzie polepszała wyniki Cost Ninja, a nie będzie konkurencją.

Dedykuj Osobę Do Zakupów Instancji Reserved
Za zakup instancji Reserved powinna odpowiadać jedna osoba, która podejmuje decyzje niezależnie od powyższych. Instancje reserved można kupować w dowolnym momencie i ich ilość jest równomiernie propagowana na określone instancje.
Ta osoba powinno dbać o to, aby stosunek instancji reserved do on demand był jak najwyższy.
Ta osoba powinna pracować z Cost Optimization Group. Ta osoba powinna umieć dodawać i odejmować. Czasami mnożyć i dzielić.
Wprowadź w Firmie Kalendarz Kosztowy
Wiedz, że nic Ci nie ucieknie. Dodaj w kalendarzu daty na każdą z wymienionych powyżej opcji, np.
- 20 – Generowanie Raportów
- 23 – Wybór Cost Ninja i Dzielenie Się Dobrymi Metodami
- 25 – Cost Optimization Group przedstawia rekomendacje
- 26 – Osoba od Instancji Reserved Analizuje Dane
- 27 – Osoba od Instancji Reserved Przedstawia Raport
- 28 – Cost Optimization Group i Osoba od Instancji Reserved Dokonują Zakupów i Optymalizacji Procesów
Wprowadź Na Poziomie CFO Koszt Per Aplikacja
A może optymalizacja kosztowa nie jest najważniejsza w Twoje organizacji. Niech w takim wypadku CFO określi ile max. może kosztować infrastruktura per user per aplikacja.
Jeżeli działowi Dev i Ops uda się dojść do tego wyniku, pozwól im zatrzymać nadwyżki na kolejne testy i sprawdzanie nowych rozwiązań, nowych maszyn.
Napędza to innowację i testy nowych środowisk. Tym samym zmniejsza koszty. Kosztowy Paradoks.
Wysyłaj Raporty Wewnątrz Organizacji
Wczoraj: Kilka zakupów, kilka razy w roku, przez kilku ludzi.
Dzisiaj: Wiele małych decyzji, kilka razy dziennie, przez wielu ludzi.
Ważne jest, aby informacja o kosztach była spójna w organizacji i dostępna w odpowiednich proporcjach dla poszczególnych grup.
Oto pomysł jak to zrobić:
- Raz w miesiącu wysyłasz dla CFO informację o zmiennej biznesowej oraz jednostkowej per projekt, z linkiem do bardziej szczegółowego raportu. Np. Projekt Mrok – 750500 nowych użytkowników w 2015.07. Spadek zmiennej jednostkowej w AWS o 100% z $0.02 do $0.01 per użytkownik. Ładny wykres z czasowym wzrostem użytkowników i spadkiem kosztów w chmurze per projekt to Twój klucz do sukcesu.
- Raz w tygodniu przesyłaj podobny raport do CIO i dyrektorów IT. Dodaj więcej informacji o jednostkach i aspektach związanych z Cost Ninja oraz planami kosztowymi. Twój CIO ma wiedzieć o budżetach i zmianach kosztowych w pierwszej kolejności
- Codziennie wysyłaj szczegółowe zestawienie do wszystkich zainteresowanych pracujących przy projektach. Wysyłaj też podsumowanie jak radzą sobie inne zespoły.
Zatrudnij Kogoś Kto Zrobi To Wszystko Za Ciebie
Wdrażając rozwiązanie w chmurze duża część moich klientów próbuje porównać rozwiązania 1:1. „Poproszę o wycenę 2 maszyn. Windows 2012R2. 30 GB dysku, etc.”. Ile zapłacę na godzinę?
Jest to sposób na podejście do chmury, ale mam nadzieję, że powyższe przykłady pokazały Ci, że istnieje inna droga. Wprowadzenie zmian technologicznych i organizacyjnych może sprawić, że koszt przestanie mieć znaczenie i stanie się elementem umacniającym zespoły.
Masz pytanie napisz. Zawsze odpisuję.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.