Miliony zapytań do bazy za mniej niż $2 – budujemy tanią aplikację w chmurze Azure


2 miliony zapytań do API, ponad 6 milionów zapytań od bazy, a wszystko to za mniej niż $2. Jak to możliwe?
Dzisiaj chciałbym Ci pokazać, jak dzięki odrobinie wiedzy o chmurze możesz napisać tanią, ale niesamowicie wydajną aplikację.
“Potrzeba matką wynalazków”
Jak wiesz, Chmurowisko nie tylko pomaga firmom wdrażać chmurę publiczną, ale posiada też platformę szkoleniową Szkoła Chmury (swoją drogą szykują się tam spore zmiany i fantastyczne nowe programy, ale szczegóły niech na razie pozostaną słodką tajemnicą?). Szkolą się na niej zarówno indywidualni użytkownicy, jak i pracownicy organizacji, z którymi współpracujemy.
Czasem zdarza się, że jakieś przedsiębiorstwo prosi nas o przygotowanie raportu z postępów nauki swoich podwładnych. Niestety, ponieważ platforma Szkoły Chmury siedzi na WordPressie, nie oferuje możliwości generowania zbiorczych raportów. Można za to podejrzeć postępy konkretnego użytkownika.
Dopóki próśb o takie raporty było niewiele, nie było problemu. Gdy trzeba było przygotować raport, ktoś z naszego zespołu zasiadał do WP i ręcznie generował stosowne dokumenty. Jednak po jakimś czasie takie zapytania od Klientów zdarzały się coraz częściej. Gdy generowanie raportów zaczęło zajmować cały dzień, miarka się przebrała. Trzeba było coś z tym zrobić.
Rozwijanie systemu „legacy”
No i zrobiłem. Usiadłem, zgłębiłem trochę kodu w PHP (ostatni raz programowałem w tym języku, jak miałem 16 lat;) i napisałem wtyczkę, która generowała raport, bazując na liście mailingowej.
I jak? Wiadomo – u mnie działało. Gorzej z produkcją, gdzie polecenie generowania raportu dla 15 użytkowników wykonywało ponad 1000 zapytań do bazy danych. W ten sposób cała strona zawieszała się na dobre kilka minut.
A może chmura?
Nie mogliśmy tego tak zostawić. Podjęliśmy decyzję, że będziemy zbierać dane w chmurze i napiszemy kilka funkcji do generowania raportów. Był tylko jeden warunek – rozwiązanie nie mogło być za drogie.
Bazując na swoim doświadczeniu i wiedzy, stwierdziłem, że użyję Azure Functions i Azure Table Storage. Mam nadzieję, że Azure Fuctions nie muszę nikomu przedstawiać. Jest to usługa serverless, w której płacimy za liczbę wywołań i zasoby użyte podczas wywołania. Co innego Azure Table Storage.
Azure Table Storage – prosta, lecz potężna baza danych
Azure Table Storage – nieco mniej popularna od Functions usługa – jest to bardzo tania baza danych, również dostępna w modelu serverless. Ma ona co prawda kilka ograniczeń, ale znając je, jesteśmy w stanie stworzyć tanią i wydajną aplikację.
Azure Table Storage to baza kolumnowa. Możemy w niej przechowywać proste typy, takie jak String, int, DateTime, float. Każda tablica ma kilka domyślnych pól (kolumn):
- TimeStamp – pole typu DateTime, zarządza nim serwer i zmienia się za każdym razem przy modyfikacji wiersza (encji).
- Partition Key – pole typu String, definiuje na której partycji znajduje się wiersz (encja). Gdy wykonujemy operację dodania, modyfikacji lub usunięcia wiersza, musimy podać jego wartość.
- Row Key – to również String, który wymagany jest razem z Partition Key do wykonywania wszelkich operacji.
Partycje mogą znajdować się na różnych serwerach, a każdy wpis w tablicy musi mieć unikalny identyfikator, który składa się z kombinacji Partition Key i Row Key:

Możemy mieć kilka wpisów z takim samym Row Key lub Partition Key (Ba! Nawet zaleca się, żeby niektóre dane trzymać na tej samej partycji). Ważne, żeby kombinacja Partition Key + Row Key była unikalna dla całej tabeli.
Zasady zapisu danych w Azure Table Storage są w miarę proste. Natomiast jeśli chodzi o odczyt danych, mamy tutaj więcej ograniczeń.
Możemy porównać, czy dane w tabeli z naszym zapytaniem są względem siebie większe, mniejsze, czy równe. Dla danych liczbowych takie możliwości są wystraczające. Gorzej w przypadku danych typu String. Chyba że skorzystamy z kilku przydatnych tricków.
Azure Table Storage – praca ze stringami
W usłudze bazodanowej Azure wielkość liter podczas wyszukiwania ma znaczenie lub nie ma znaczenia. Zależy to od tego gdzie uruchomimy zapytanie. Jeśli uruchamiamy lokalnie za pomocą emulatora to ma. Czyli gdy w bazie mamy zapisanego stringa „FOO” i uruchomimy zapytanie, które szuka „foo”, znajdziemy naszą encję bez problemu. Ale gdy uruchamiamy takie zapytanie już w chmurze (a nie w emulatorze), to niestety nie znajdziemy go.
Do niedawna był błąd który nie uwzględniał wielkości nawet w chmurze ale został naprawiony.
Jeśli znamy tylko początek stringa, możemy użyć zapytania, które szuka wartości większych niż znany nam początek. Na przykład mamy stringa „FOO Bar 2000” i szukając stringów większych niż „Foo”, znajdziemy go bez problemu. Ale zapytanie zwróci nam też na przykład stringa „ZZZZ”, dlatego warto taki request ograniczać. Jak? Możemy na przykład dodać warunek że szukany string musi być mniejszy niż „Fooz”. Osobom zainteresowanym tematem polecam ten artykuł.
Co do wydajności zapytań, to jeśli dobrze je sformułujemy, zwracanie wyniku z bazy może potrwać 20 ms. Natomiast w przypadku nieumiejętnie napisanego zapytania, operacja może się ciągnąć i ciągnąć w nieskończoność. Dlatego najlepiej sprawdzają się zapytania, w których mamy zdefiniowany zarówno Partition Key, jak i Row Key – wtedy nasza baza wie dokładnie, gdzie szukać.
- Jeśli zdefiniujemy Partition Key i tylko częściowo Row Key lub inną kolumnę, wydajność spada, ale baza danych sprawdza tylko jedną partycję. Jeżeli znajduje się na niej niezbyt dużo danych, zapytanie wykona się dość szybko. Warto jednak wiedzieć, że wydajność bazy spada też przy przeszukiwaniu kolumny innej niż Row Key.
- Jeśli nie zdefiniujemy ani Partition Key, ani Row Key, wtedy operacja trwa najdłużej, bo baza danych musi zeskanować całą tabelę, żeby znaleźć nasze dane. Im większa baza danych, tym dłużej to zajmie.
- Jeżeli zapytanie zwraca dużą liczbę wyników (powyżej 1000) lub zapytanie trwa długo (więcej niż 5s), Azure Table Storage nie zwróci nam od razu wszystkich danych, a jedynie ich część oraz dane do kontynuowania zapytania.
Azure Functions – tania moc obliczeniowa
Azure Functions to głównie kod w C#. Z ciekawszych „zabiegów” dodałem do niego wstrzykiwanie zależności.
Żeby zrekompensować braki zapytań do Azure Table Storage, użyłem LINQ. Pozwoliło mi to na sprawną pracę z listami obiektów, które odpowiadały danym w tabeli. Dzięki funkcji join mogłem nawet dodawać dane z innych list.
Aby przyspieszyć dodawanie i aktualizowanie dużej ilości danych, niezastąpione okazało się wykonanie ich asynchronicznie. Umiejętne wykorzystanie asynchronicznych funkcji pozwoliło mi przyspieszyć wykonanie funkcji z 3 s do 300 ms, co ma spore przełożenie na koszty Azure Functions.
Niestety na wywołania asynchroniczne trzeba uważać. Zbyt duża liczba asynchronicznych zapytań do tabeli potrafi rzucać błędami.
Jak to działa u nas?
Na stronie z lekcją jest kawałek JavaScriptu, który mierzy czas spędzony na stronie, i co 30 sekund wysyła informację o upływie czasu, adresie e-mail użytkownika, oraz o ID kursu i lekcji. Funkcja odbiera te dane – wyciąga aktualny postęp, dodaje kolejne 30 sekund oraz decyduje, czy lekcję należy uznać za ukończoną na podstawie danych z tabeli z kursami. To wszystko zapisuje do bazy w mniej niż 100 ms.
Dodatkowo funkcja zapisuje informację, że dla tego kursanta i kursu trzeba odświeżyć schowek. W schowku przechowujemy dane na temat liczby lekcji ukończonych przez kursanta, np. kurs o ID 123, użytkownik Piotrek obejrzał 23 lekcji. Tabela z postępami zawiera dokładne dane na temat postępu użytkownika w danej lekcji.
Dlaczego tworzymy schowek? Odpowiedz jest bardzo prosta – ze względu na wydajność i ograniczenia bazy danych. W SQL-u moglibyśmy napisać zapytanie, które sprawdza liczbę ukończonych lekcji. W Azure Table Storage takiej możliwości nie ma.
Gdy potrzebujemy wygenerować raport, przechodzimy na stronę, na której wpisujemy listę adresów mailowych, wybieramy kurs i w zamian dostajemy raport dla wybranych użytkowników.
Ile to wszystko kosztuje?
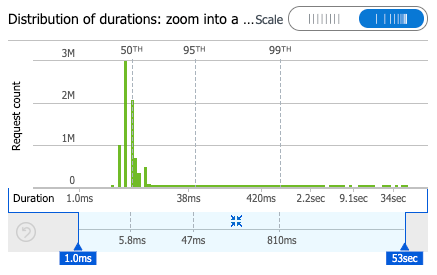
Mało, bardzo mało. Droższa niż same funkcje i baza danych bywa analityka. W ostatnim miesiącu funkcje do generowanie postępów użytkowników kosztowały nas… 1 euro. Funkcje zostały wywołane ponad dwa miliony razy, a średni czas odpowiedzi wyniósł 50 ms.

A tak prezentuje się rozkład czasów wywołań:

Dlaczego jest tak tanio?
W Azure Functions płacimy za dwie rzeczy – wywołania funkcji i zużyte zasoby. Cennik usługi znajdziesz tutaj (użyłem cen z Europy Północnej).
Koszt usługi wynosi 0,169 euro za milion wywołań. Proste. Koszt zasobów jest już ciężej wyliczyć. Płacimy tu bowiem za czas i zużytą pamięć. Zużycie jednego gigabajta przez jedną sekundę kosztuje 0,000014 euro. Ale jeśli nasz funkcja trwała krócej i zużyła mniej pamięci, zapłacimy mniej.
UWAGA! Azure zaokrągla zużycie do najbliższych 128 MB pamięci i 1 ms. Ale minimalny czas wykonywania i pamięć dla pojedynczego wykonania funkcji to 128 MB RAM-u i 100 ms.
Oznacza to, że nawet jeśli mamy ultraszybką funkcję, która trwa tylko 10 ms i używa 10 MB RAM-u, to i tak zapłacimy za nią tyle, co za funkcję trwającą 100 ms i pochłaniającą 128 MB. Warto o tym pamiętać. Dodatkowo co miesiąc otrzymujemy od Azure bezpłatny przydział 400 000 GB-s (sekundy gigabajta pamięci) i 1 miliona wykonań.
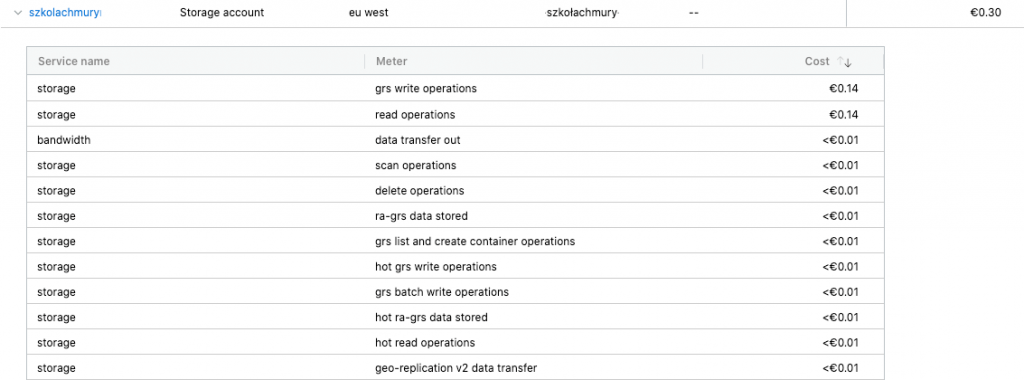
W naszym przypadku storage kosztował 0,5 euro (storage funkcji, nie tylko tabeli). Koszt samych tabeli wyniósł 0,3 euro.
Zapytań do bazy danych było „tylko” 8,5 miliona, a średni czas odpowiedzi wyniósł 32 ms. Jednak rozkład czasów wywołań prezentuje się tu nieco inaczej. Mamy kilka dłuższych, bo bardziej skomplikowanych, zapytań służących do generowania raportów.
Tabele Azure są rozliczane dość prosto – zajrzyj tutaj. W zależności od tego, jak chcemy rozlokować dane, jest to koszt od 0,0380 euro do 0,1067 euro per GB. Z kolei za 10 000 operacji na tabelach płacimy 0,000304 euro. Dość tanio. Najdroższa tak naprawdę była zatem analityka. Zapłaciliśmy za nią 4,71 euro.

Tania chmura, problem z głowy
Jak widzisz, aplikacja, którą stworzyłem, nie jest zbytnio skomplikowana. Jednak najważniejsze, że idealnie spełnia swoje zadanie. Pozwoliła nam zmniejszyć czas generowania raportów ze szkoleń od kilku godzin do kilku sekund. Nieźle!
Nasze rozwiązanie w chmurze jest tanie, a jego instalacja to tylko kilka kliknięć w IDE. Z kolei z Application Insights monitoring aplikacji to czysta przyjemność.
To samo, tylko w AWS
Co ciekawe, bardzo podobną aplikację można stworzyć w AWS. Azure Functions zamieniamy na Lambdę, a Azure Table Storage – na DynamoDb. Użycie DynamoDb byłoby co prawda troszkę droższe, ale jest to bardziej rozbudowana baza, dająca więcej możliwości. Jakich?
Tutaj chciałbym Ci polecić wystąpienie Dave’a Killiana, inżyniera z ekipy Snapchatu. Video ma już swoje lata, ale według mnie ciekawie obrazuje, jak działa chmura – im lepiej znasz daną usługę, tym lepiej możesz ją wykorzystać.
Mam nadzieję, że przekonałem Cię, że chmura może być tania i nadaje się również do małych projektów. A jeśli masz jakieś uwagi, pytania albo wątpliwości, napisz do mnie na [email protected]. Chętnie pomogę!
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.