Bliżej i Szybciej w Globalnej Skali. Prześwietlamy Usługę Lambda@Edge


Serverless. Słowo, o którym w ubiegłym roku słyszał chyba każdy programista i architekt systemów IT. Wszystko wskazuje na to, że rok 2019 będzie dla architektury bezserwerowej jeszcze ciekawszy. Wiele osób sądzi, że właśnie w ciągu najbliższych kilku miesięcy rozwiązania serverless będą rozwijały się szybciej niż jakakolwiek inna dziedzina IT. No, może poza kolejnymi frameworkami Node.Js 😉
Kiedy pada hasło serverless, pierwsze, co przychodzi mi do głowy, to usługa AWS Lambda. Praktycznie każdy o niej słyszał, nie każdy jednak wie, że Lambdę można uruchamiać także w usłudze CloudFront, czyli w oferowanym przez Amazon rozwiązaniu content delivery network. Dzieje się tak dzięki usłudze Lambda@Edge.
Jak uruchomić funkcję Lambda@Edge?
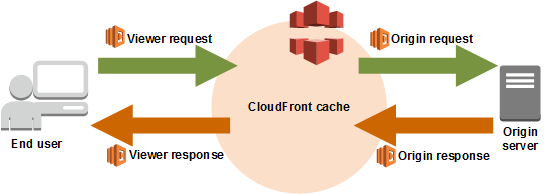
Funkcję Lambda@Edge możemy wywołać za pomocą czterech eventów, które mamy do dyspozycji w CloudFront:
- Viewer Request. Zachodzi, kiedy CloudFront otrzymuje żądanie od użytkownika przed sprawdzeniem, czy dane są w schowku.
- Origin Request to event, który wywoływany jest jedynie, kiedy żądanie przekazane jest do źródła. Jeżeli dane są już w schowku, ten event nie jest uruchamiany.
- Origin Response uruchamiany jest pomiędzy momentem, w którym CloudFront otrzymuje odpowiedź od źródła, a chwilą, gdy odpowiedź ląduje w schowku. Co istotne, Origin Response zachodzi także wtedy, gdy źródło zwróci błąd.
- Viewer Response uruchamiany jest z kolei przed zwróceniem obiektu do użytkownika. Niezależnie od tego, czy był w schowku, czy nie.
Kiedy użyć danego eventu?
Wybór metod uruchamiających Lambda@Edge jest całkiem spory. Nasuwa się zatem pytanie, kiedy użyć poszczególnych eventów. W każdym przypadku trzeba do tej kwestii podejść indywidualnie. Przygotowałem jednak kilka wskazówek, które mogą pomóc Ci w wyborze.
- Jeżeli chcemy uruchomić naszą funkcję dla każdego żądania, skorzystajmy z eventu ViewerRequest lub ViewerResponse. Pierwszy będzie uruchomiony zawsze, drugi prawie za każdym razem.
- W przypadku gdy chcemy zmodyfikować samo żądanie tak, że zmieni ono odpowiedź źródła, użyjmy eventu OriginRequest.
- Chcąc zmienić obiekt, który zostanie zapisany w schowku CloudFront, użyjmy eventu OriginRequest lub OriginResponse.
Ograniczenia Lambda@Edge
Lambda@Edge w porównaniu z klasycznymi funkcjami Lambda posiada wiele ograniczeń. Najważniejszym z nich, przynajmniej dla mnie, jest fakt, że funkcje Lambda@Edge możemy pisać tylko w Node.Js. O innych językach możemy jak na razie zapomnieć. Mam jednak nadzieję, że wkrótce to się zmieni.
Drugą kwestią są warstwy i zmienne środowiskowe. Zapomnijcie o nich! Te drugie możemy zastąpić AWS Systems Manager Parameter Store. Ale zawsze wprowadzi to jakieś opóźnienia. A maksymalne timeouty w Lambda@Edge też mamy krótsze. Dla OriginRequest i OriginResponse to 30 sekund. Dla eventów ViewerRequest oraz ViewerResponse to tylko 5 sekund.
Do tego dochodzi jeszcze więcej limitów. Na szczęście sporo z nich to tak zwane ograniczenia miękkie, co oznacza, że możemy poprosić o ich zwiększenie. Także sama wielkość funkcji, rozmiar odpowiedzi oraz maksymalna ilość pamięci, którą możemy przydzielić funkcjom @Edge, są mniejsze od standardowych.
A jak korzystać z Lambda@Edge? Oto przykład
Spróbujemy zaimplementować przykładową funkcję Lambda@Edge. Nasze rozwiązanie pozwoli na generowanie za pomocą Lambdy strony www. Jej treść będziemy zmieniali w zależności od kraju, z którego łączy się nasz użytkownik.
Jeżeli wykorzystamy usługę CloudFront, czy to bezpośrednio, czy też implementując nasze API w usłudze API Gateway jako Edge Optimized, w żądaniu zostaną nam przekazane różne nagłówki. Między innymi nagłówek CloudFront-Viewer-Country.

Na podstawie tego nagłówka funkcja Lambda@Edge będzie generowała kod HTML zwracany do użytkownika.
Nasze rozwiązanie będzie składało się z kilku elementów:
- statycznej strony www w usłudze S3
- dystrybucji CloudFront
- funkcji Lambda podpiętej pod event OriginRequest
Proponuję utworzyć zarówno koszyk S3 jak i funkcję Lambda w regionie N. Virginia. Funkcje Lambda@Edge możemy tworzyć tylko w tym regionie!
1. Piszemy kod strony WWW
W pierwszym kroku musimy utworzyć bucket S3, wgrać do niego poniższy kod i uruchomić w tym koszyku hosting. Kod strony www, która będzie wyświetlana z S3 jest bardzo prosty.
Hello unknown from S3
Strona będzie po prostu nas informowała, że nie można rozpoznać kraju, z którego użytkownik łączy się z naszą usługą. Do tej strony „podepniemy” też dystrybucję CloudFront.

Cała magia będzie się działa w funkcji Lambda@Edge umieszczonej w CloudFront. To ona będzie generowała właściwą odpowiedź w zależności od kraju, z którego pochodzi nasz użytkownik.
1. Tworzymy funkcję Lambda
W kolejnym kroku musimy utworzyć funkcję Lambda. Pamiętajcie o regionie – N. Virginia.
Tworzymy zwykłą Lambdę, jako runtime wybieramy Node.Js 8.10. Wystarczy nam domyślna rola, która nada uprawnienia do zapisu logów w usłudze CloudWatch.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
}
]
}
Teraz musimy dodać Lambda@Edge do zaufanych (Trust relationships).

Po wprowadzeniu tych zmian nasza polityka powinna wyglądać tak:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": ["lambda.amazonaws.com", "edgelambda.amazonaws.com"]
},
"Action": "sts:AssumeRole"
}
]
}
Kod samej funkcji jest prosty. W nagłówkach wyszukuje kraj, z którego łączy się nasz użytkownik i wstawia go do kodu HTML, który jest zwracany do użytkownika. Jeżeli nagłówka nie ma, zwraca po prostu żądanie.
'use strict';
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
const headers = request.headers;
console.log('request', request);
if (
headers['cloudfront-viewer-country'] &&
headers['cloudfront-viewer-country'][0].value
) {
const cloudFrontCountryCode = headers['cloudfront-viewer-country'][0].value;
console.log('countryCode', cloudFrontCountryCode);
const response = {
status: '200',
statusDescription: 'OK',
headers: {
'cloudfront-viewer-country': [
{
key: 'CloudFront-Viewer-Country',
value: cloudFrontCountryCode,
},
],
'cache-control': [
{
key: 'Cache-Control',
value: 'max-age=100',
},
],
'content-type': [
{
key: 'Content-Type',
value: 'text/html',
},
]
},
body: `
Hello ${cloudFrontCountryCode} from Lambda @Edge!
`, }; callback(null, response); } callback(null, request); };
3. Ustalamy wersję
O wersjach i aliasach funkcji Lambda pisałem już na naszym blogu. Aby nasza Lambda mogła być wykorzystana jako funkcja Lambda@Edge, musimy opublikować jej wersję. W usłudze CloudFront podepniemy później ARN opublikowanej wersji.
W konsoli wybieramy menu Actions i opcję Publish new version. Możemy dodać też jakiś opis. Po chwili nasza wersja będzie gotowa.

Po utworzeniu wersji w górnej części konsoli wyświetli nam się ARN dla naszej funkcji.

Skopiujmy go sobie, będzie potrzebny za chwilę.
4. Dystrybucja CloudFront
Mamy nasz bucket, mamy Lambdę, stwórzmy teraz powiązaną z nimi dystrybucję CloudFront.
- Jako Origin Domain Name wybieramy nasz bucket. To z niego będą pobierane w razie potrzeby dane.
- Przekierowujemy też wywołania HTTP na HTTPS w sekcji Default Cache Behavior Settings.

- W kolejnym kroku musimy dodać do białej listy nagłówek, którym będziemy się posługiwali.

- Teraz najważniejsze. Musimy podpiąć funkcję Lambda pod dystrybucję. Wybieramy interesujący nas event, czyli OriginRequest i wklejamy ARN do naszej funkcji Lambda. Pamiętajcie, że powinien to być ARN opublikowanej wersji.

- I to właściwie wszystko. Klikamy [Create Distribution] i nasza dystrybucja zaczyna się tworzyć.
Po 15-30 minutach dystrybucja powinna być gotowa. Możemy przejść do testowania naszego rozwiązania.
CloudFront – Testy i logi
Każda dystrybucja CloudFront ma swoje DomainName. Skorzystajmy z przeglądarki i przetestujmy jej działanie.
Włączamy narzędzia programisty w Chrome, wklejamy adres naszej dystrybucji w przeglądarce i… voilà!

Dostaliśmy odpowiedź od naszej funkcji Lambda@Edge.
W przeglądarce, w zakładce Network, klikamy w odpowiedź z serwera i sprawdzamy nagłówki.

Sprawdźmy teraz, co mamy w logach. Wchodzimy do usługi CloudWatch w regionie N. Virginia i… nic tam nie ma.
Na początku mnie to także zdziwiło. Lambda@Edge zapisuje bowiem logi w regionie, w którym jest wywoływana (albo najbliższym). Ja łączyłem się z Polski, sprawdźmy więc, co słychać we Frankfurcie.

Jak widać, wszystko jest w porządku. Nasza Lambda zadziałała, a logi zostały zapisane.
Odświeżmy stronę i sprawdźmy, co się stanie:

Tym razem nasza strona została załadowana ze schowka, bez uruchamiania funkcji Lambda@Edge. W logach nie będziemy mieli zatem nic nowego.
Spróbujmy połączyć się teraz z innego kraju. Najlepiej wykorzystać do tego jakieś połączenie VPN. Ja użyję PureVPN ale możecie użyć np. TunnelBear. Na potrzeby naszego testu wystarczy, a jest darmowy. Połączyłem się z serwerem VPN w Holandii.

Kolejna próba w Chrome i przenosimy się do kraju tulipanów.

Tym razem nagłówek x-cache miał wartość Miss from cloudfront. Dlaczego? Było to pierwsze wywołanie z Holandii i CloudFront nie miał jeszcze w schowku właściwej odpowiedzi. Ponownie zadziałała nasza Lambda@Edge:

Usuwamy zasoby
Usuwanie zasobów związanych z Lamda@Edge przysparza nieco problemów. Pamiętajmy, że nasze funkcje replikowane są do poszczególnych miejsc docelowych. W moim przypadku przy kasowaniu Lambda@Edge zadziałał taki scenariusz:
- Odłączyłem funkcję od dystrybucji CloudFront. Można to zrobić w ustawieniach dystrybucji w sekcji Behavior.
- Dałem CloudFrontowi trochę czasu. Przynajmniej 30 minut. (Raz musiałem czekać prawie 2 godziny!)
- Usunąłem funkcję.
Jeżeli używamy CloudFormation, prawie na pewno będzie konieczna dwukrotna próba usunięcia stacka. Za pierwszym razem operacja usunięcia funkcji się nie powiedzie.
Co z tą Lambdą@Edge?
Udostępniona w 2017 roku usługa Lambda@Edge jest potężnym narzędziem o wielu zastosowaniach.
Za jej pomocą możemy na przykład sprawdzać wartości cookies w żądaniach i na tej podstawie przekierowywać użytkowników na inne adresy URL. Korzystając z nagłówka user-agent, możemy obługiwać różne rozmiary zdjęć. Nie będzie także wielkim problemem wykonanie autoryzacji żądań.
Jeśli chcielibyście odkryć jeszcze więcej zastosowań Lambda@Edge, w oficjalnej dokumentacji można znaleźć wiele przykładów na ciekawe wykorzystanie tej usługi. Miłej zabawy!
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.