Big Data Nie Jest Trudne (Czyli Zapomnij O Teorii I Sprawdź Na Własnej Skórze)


Pokażę wam jak w prosty sposób i przy minimalnych nakładach pracy przygotować swój własny klaster Elastic MapReduce w AWS czyli środowisko Hadoop i aplikacji z nim związanych.
Dla tych którzy śledzą moje poczynania na blogu Big Data Lab – ostatnim razem przygotowywaliśmy środowisko, w którym przeprowadzaliśmy od zera instalację Ubuntu, konfigurację Chef��’a aby w pełni zautomatyzować proces przygotowania środowiska. Oczywiście jest to bardzo dobre rozwiązanie dla małych testów czy udowadniania sobie że się uda.
Automatyzacja Wdrożenia z Amazon Elastic MapReduce
AWS powyższe kroki automatyzuje w takim stopniu, że pozostawia nam jedynie do wypełnienia formularz tworzenia usługi Elastic Map Reduce. Rozpocznijmy zatem tworzenie środowiska, przechodząc z konsoli głównej AWS do usługi EMR.

Wystarczy teraz kliknąć w „Create Cluster” i rozpoczynamy wypełnianie naprawdę bardzo prostego formularza tworzenia naszej usługi.
Ustawiamy nazwę, np. „bigdatalab” a następnie lokalizację S3 dla składowania logów środowiska czyli „s3://bigdatalab/logs/”
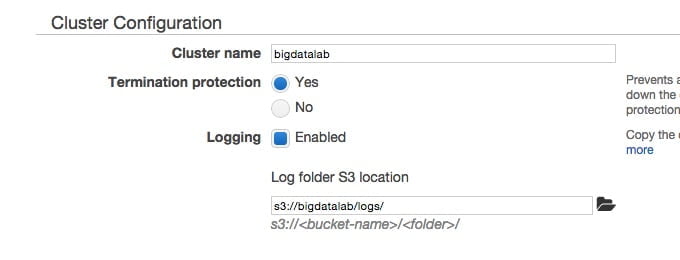
Niezbędnym krokiem jest także wybór w którym VPC uruchomione zostaną nasze instancje On Demand oraz Spot, oraz która Availability Zone i podsieć będą je obsługiwały.
Wybór Instancji Dla AWS EMR
Decyzją, która ma kluczowy wpływ na koszty naszego środowiska testowego jest wybór typów instancji które AWS powoła na potrzeby poszczególnych ról klastra.
Dla instancji Master – trzymającej najważniejsze informacje dotyczące budowy oraz elementów składowych Hadoop, stawiamy na instancji On Demand. Jej utrata wiązała by się z całkowitą utratą danych oraz konfiguracji. Powołujemy namniejszą możliwą instancję m1.medium.
Dla instancji Core – bezpiecznie było by dać przynajmniej jedną instancję On Demand, jednak na potrzeby testów kuszące jest wykorzystanie instancji Spot, które w rezultacie pozwalają na kilkukrotne obniżenie kosztów. Licytować będziemy instancję m1.medium w cenie 0.011$.
Dla instancji Task – podobnie uruchamiamy instancje m1.medium jako Spot.
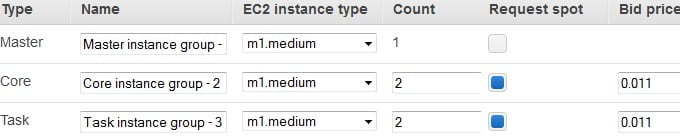
To już wszystkie pola formularza jakie potrzebujemy zmienić aby wystartować nasz klaster Hadoop w środowisku AWS Elastic Map Reduce.
Start Środowiska Amazon Elastic MapReduce
Po kilku dłuższych chwilach możemy zajrzeć do zakładki EC2 i sprawdzić czy instancje On Demand oraz instancje Spot są powoływane.
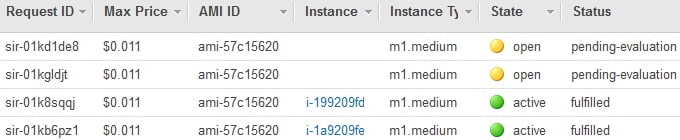
W zakładce EC2/Spot Instances możemy zaobserwować że nasza licytacja wolnych zasobów AWS po części się już powiodła, dwa z serwerów mają status „fulfilled”, dostaliśmy przydział i maszyny zaczną się uruchamiać.
Po kilku dłuższych chwilach zaglądając do EC2/Instances widzimy że wszystkie nasze elementy składowe klastra Hadoop, czyli węzły Master, Core i Task.

Wracając do EMR, nasz klaster ma już status Running, wraz z instancjami składowymi.

Czas Na Prawdziwe Testy Big Data
Pozostaje nam zalogować się po SSH i zweryfikować czy uruchomi nam się Hive.
Wystarczy teraz wykonać kopiowanie naszego pliku danych który wykorzystywaliśmy ostatnim razem do HDFS. Dla uproszczenia plik ten wcześniej skopiowałem na S3, do ścieżki s3:// bigdatalab/input/Batting.csv
Ponieważ kopiowanie wykonujemy bezpośrednio z S3 do HDFS, komenda będzie nieco inna, podobnie jak lokalizacja docelowa w HDFS czyli „/tmp”.
hadoop distcp s3n://bigdatalab/input/Batting.csv hdfs:///tmp
Tak naprawdę będzie to jedyna różnica w stosunku do tego co wykonaliśmy na testach instalacji lokalnej, także dalsze kroki możemy po prostu skopiować i wkleić, pamiętając aby podmienić ścieżkę HDFS z „/user/root” na „/tmp”
LOAD DATA INPATH '/tmp/Batting.csv' OVERWRITE INTO TABLE temp_batting;
Dalsze kroki pozostawiam twojej wyobraźni, możesz kontynuować przeklejanie z bigdatalab.pl lub spróbować swoich własnych sił, by przekonać się że Big Data nie jest wcale takie trudne, a rozwiązania w Cloud, poza modelem rozliczania przynoszą oszczędność czasu oraz elegancję I za razem prostotę przygotowania środowiska.
Chcesz wiedzieć ile kosztują usługi w Amazon Web Services (w tym Elastic MapReduce)? Sprawdź w artykule Za Co Płacimy w Amazon Web Services.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.
Przed nami nowy rozdział! Chmurowisko dokonało połączenia z polskim Software Mind – firmą, która od 20 lat tworzy rozwiązania przyczyniające się do sukcesu organizacji z całego świata…
Grupa Dynamic Precision podjęła decyzję o unowocześnieniu swojej infrastruktury. Razem z Oracle Polska prowadzimy migrację aplikacji firmy do chmury OCI.
Już 21 czerwca dowiesz się, jak możesz wykorzystać AI w Twojej firmie. Damian Mazurek i Piotr Kalinowski wprowadzą Cię w świat sztucznej inteligencji i LLM.


Zapisz się do naszego newslettera i
bądź z chmurami na bieżąco!
z chmur Azure, AWS i GCP, z krótkimi opisami i linkami.